
“Neural rendering in a room: amodal 3D understanding and free-viewpoint rendering for the closed scene composed of pre-captured objects” by Yang, Zhang, Li, Cui, Fanello, et al. …
Conference:
Type(s):
Title:
- Neural rendering in a room: amodal 3D understanding and free-viewpoint rendering for the closed scene composed of pre-captured objects
Presenter(s)/Author(s):
Abstract:
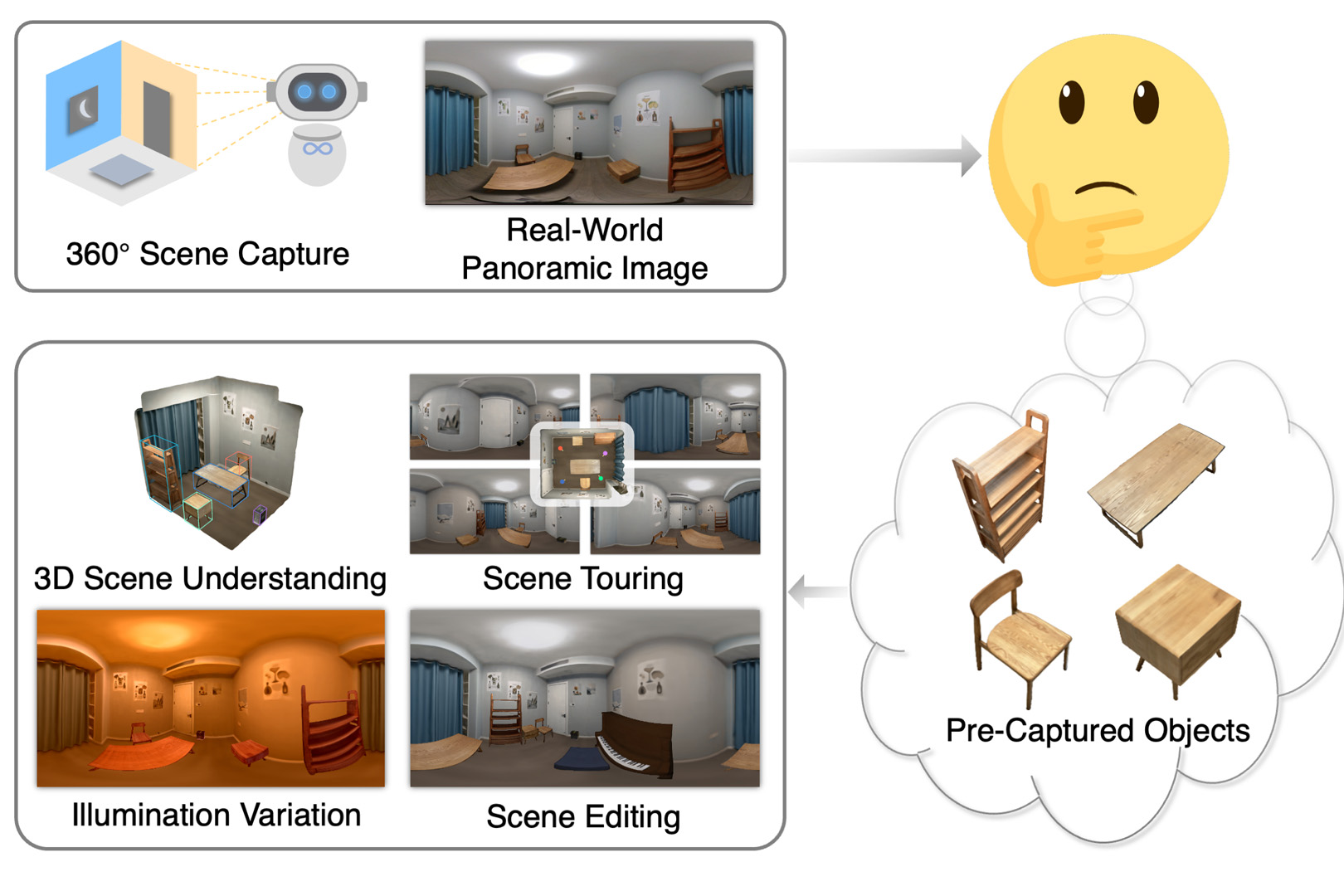
We, as human beings, can understand and picture a familiar scene from arbitrary viewpoints given a single image, whereas this is still a grand challenge for computers. We hereby present a novel solution to mimic such human perception capability based on a new paradigm of amodal 3D scene understanding with neural rendering for a closed scene. Specifically, we first learn the prior knowledge of the objects in a closed scene via an offline stage, which facilitates an online stage to understand the room with unseen furniture arrangement. During the online stage, given a panoramic image of the scene in different layouts, we utilize a holistic neural-rendering-based optimization framework to efficiently estimate the correct 3D scene layout and deliver realistic free-viewpoint rendering. In order to handle the domain gap between the offline and online stage, our method exploits compositional neural rendering techniques for data augmentation in the offline training. The experiments on both synthetic and real datasets demonstrate that our two-stage design achieves robust 3D scene understanding and outperforms competing methods by a large margin, and we also show that our realistic free-viewpoint rendering enables various applications, including scene touring and editing. Code and data are available on the project webpage: https://zju3dv.github.io/nr_in_a_room/.
References:
1. Relja Arandjelovic, Petr Gronat, Akihiko Torii, Tomas Pajdla, and Josef Sivic. 2016. NetVLAD: CNN Architecture for Weakly Supervised Place Recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition. 5297–5307.Google ScholarCross Ref
2. Armen Avetisyan, Tatiana Khanova, Christopher Choy, Denver Dash, Angela Dai, and Matthias Nießner. 2020. SceneCAD: Predicting Object Alignments and Layouts in RGB-D Scans. In European Conference on Computer Vision. Springer, 596–612.Google Scholar
3. Alexey Bokhovkin, Vladislav Ishimtsev, Emil Bogomolov, Denis Zorin, Alexey Artemov, Evgeny Burnaev, and Angela Dai. 2021. Towards Part-Based Understanding of RGB-D Scans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7484–7494.Google ScholarCross Ref
4. Wenzheng Chen, Huan Ling, Jun Gao, Edward Smith, Jaakko Lehtinen, Alec Jacobson, and Sanja Fidler. 2019. Learning to Predict 3D Objects with an Interpolation-based Differentiable Renderer. Advances in Neural Information Processing Systems 32.Google Scholar
5. James M Coughlan and Alan L Yuille. 1999. Manhattan World: Compass Direction from a Single Image by Bayesian Inference. In Proceedings of the seventh IEEE international conference on computer vision, Vol. 2. IEEE, 941–947.Google ScholarCross Ref
6. Manuel Dahnert, Ji Hou, Matthias Nießner, and Angela Dai. 2021. Panoptic 3D Scene Reconstruction From a Single RGB Image. Advances in Neural Information Processing Systems 34.Google Scholar
7. Peng Dai, Yinda Zhang, Zhuwen Li, Shuaicheng Liu, and Bing Zeng. 2020. Neural Point Cloud Rendering via Multi-Plane Projection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7830–7839.Google ScholarCross Ref
8. Saumitro Dasgupta, Kuan Fang, Kevin Chen, and Silvio Savarese. 2016. DeLay: Robust Spatial Layout Estimation for Cluttered Indoor Scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition. 616–624.Google ScholarCross Ref
9. Paul E. Debevec. 2006. Image-based Lighting. In International Conference on Computer Graphics and Interactive Techniques, SIGGRAPH 2006, Boston, Massachusetts, USA, July 30 – August 3, 2006, Courses, John W. Finnegan and Dave Shreiner (Eds.). ACM, 4.Google Scholar
10. Terrance DeVries, Miguel Angel Bautista, Nitish Srivastava, Graham W Taylor, and Joshua M Susskind. 2021. Unconstrained Scene Generation with Locally Conditioned Radiance Fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 14304–14313.Google ScholarCross Ref
11. Yilun Du, Zhijian Liu, Hector Basevi, Ales Leonardis, Bill Freeman, Josh Tenenbaum, and Jiajun Wu. 2018. Learning to Exploit Stability for 3D Scene Parsing. In NeurIPS. 1733–1743.Google Scholar
12. Stephan J Garbin, Marek Kowalski, Matthew Johnson, Jamie Shotton, and Julien Valentin. 2021. FastNeRF: High-Fidelity Neural Rendering at 200FPS. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 14346–14355.Google ScholarCross Ref
13. Steven J Gortler, Radek Grzeszczuk, Richard Szeliski, and Michael F Cohen. 1996. The Lumigraph. In Proceedings of the 23rd annual conference on Computer graphics and interactive techniques. 43–54.Google Scholar
14. Jonathan Granskog, Till N Schnabel, Fabrice Rousselle, and Jan Novák. 2021. Neural Scene Graph Rendering. ACM Transactions on Graphics (TOG) 40, 4 (2021), 1–11.Google ScholarDigital Library
15. Thibault Groueix, MatthewFisher, Vladimir G Kim, Bryan C Russell, and Mathieu Aubry. 2018. AtlasNet: A Papier-Mâché Approach to Learning 3D Surface Generation. In Proceedings of the IEEE conference on computer vision and pattern recognition. 216–224.Google ScholarCross Ref
16. Michelle Guo, Alireza Fathi, Jiajun Wu, and Thomas Funkhouser. 2020. Object-Centric Neural Scene Rendering. arXiv preprint arXiv:2012.08503 (2020).Google Scholar
17. Siyuan Huang, Siyuan Qi, Yinxue Xiao, Yixin Zhu, Ying Nian Wu, and Song-Chun Zhu. 2018a. Cooperative Holistic Scene Understanding: Unifying 3D Object, Layout, and Camera Pose Estimation. Advances in Neural Information Processing Systems 31.Google Scholar
18. Siyuan Huang, Siyuan Qi, Yixin Zhu, Yinxue Xiao, Yuanlu Xu, and Song-Chun Zhu. 2018b. Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image. In Proceedings of the European conference on computer vision (ECCV). 187–203.Google ScholarDigital Library
19. Hamid Izadinia, Qi Shan, and Steven M Seitz. 2017. IM2CAD. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 5134–5143.Google ScholarCross Ref
20. Michael M. Kazhdan, Matthew Bolitho, and Hugues Hoppe. 2006. Poisson Surface Reconstruction. In Proceedings of Eurographics Symposium on Geometry Processing. 61–70.Google Scholar
21. Byung-soo Kim, Pushmeet Kohli, and Silvio Savarese. 2013. 3D Scene Understanding by Voxel-CRF. In Proceedings of the IEEE International Conference on Computer Vision. 1425–1432.Google Scholar
22. Marc Levoy and Pat Hanrahan. 1996. Light Field Rendering. In Proceedings of the 23rd annual conference on Computer graphics and interactive techniques. 31–42.Google ScholarDigital Library
23. Zhengqin Li, Mohammad Shafiei, Ravi Ramamoorthi, Kalyan Sunkavalli, and Manmohan Chandraker. 2020. Inverse Rendering for Complex Indoor Scenes: Shape, Spatially-Varying Lighting and SVBRDF From a Single Image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2475–2484.Google ScholarCross Ref
24. Shichen Liu, Tianye Li, Weikai Chen, and Hao Li. 2019. Soft Rasterizer: A Differentiable Renderer for Image-Based 3D Reasoning. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 7708–7717.Google ScholarCross Ref
25. Shaohui Liu, Yinda Zhang, Songyou Peng, Boxin Shi, Marc Pollefeys, and Zhaopeng Cui. 2020. DIST: Rendering Deep Implicit Signed Distance Function with Differentiable Sphere Tracing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019–2028.Google ScholarCross Ref
26. Stephen Lombardi, Tomas Simon, Jason M. Saragih, Gabriel Schwartz, Andreas M. Lehrmann, and Yaser Sheikh. 2019. Neural Volumes: Learning Dynamic Renderable Volumes from Images. ACM Trans. Graph. 38, 4 (2019), 65:1–65:14.Google ScholarDigital Library
27. Andrew Luo, Zhoutong Zhang, Jiajun Wu, and Joshua B Tenenbaum. 2020. End-to-End Optimization of Scene Layout. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3754–3763.Google ScholarCross Ref
28. Arun Mallya and Svetlana Lazebnik. 2015. Learning Informative Edge Maps for Indoor Scene Layout Prediction. In Proceedings of the IEEE international conference on computer vision. 936–944.Google ScholarDigital Library
29. Ricardo Martin-Brualla, Noha Radwan, Mehdi SM Sajjadi, Jonathan T Barron, Alexey Dosovitskiy, and Daniel Duckworth. 2021. NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7210–7219.Google ScholarCross Ref
30. Wojciech Matusik, Hanspeter Pfister, Matthew Brand, and Leonard McMillan. 2003. A Data-Driven Reflectance Model. ACM Trans. Graph. 22, 3, 759–769.Google ScholarDigital Library
31. Ben Mildenhall, Pratul P. Srinivasan, Rodrigo Ortiz Cayon, Nima Khademi Kalantari, Ravi Ramamoorthi, Ren Ng, and Abhishek Kar. 2019. Local Light Field Fusion: Practical View Synthesis with Prescriptive Sampling Guidelines. ACM Trans. Graph. 38, 4 (2019), 29:1–29:14.Google ScholarDigital Library
32. Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. 2020. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In European conference on computer vision. Springer, 405–421.Google ScholarDigital Library
33. Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. 2022. Instant Neural Graphics Primitives with a Multiresolution Hash Encoding. arXiv preprint arXiv:2201.05989 (2022).Google Scholar
34. Yinyu Nie, Xiaoguang Han, Shihui Guo, Yujian Zheng, Jian Chang, and Jian Jun Zhang. 2020. Total3DUnderstanding: Joint Layout, Object Pose and Mesh Reconstruction for Indoor Scenes From a Single Image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 55–64.Google ScholarCross Ref
35. Michael Niemeyer, Lars M. Mescheder, Michael Oechsle, and Andreas Geiger. 2020. Differentiable Volumetric Rendering: Learning Implicit 3D Representations Without 3D Supervision. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3501–3512.Google ScholarCross Ref
36. Michael Oechsle, Songyou Peng, and Andreas Geiger. 2021. UNISURF: Unifying Neural Implicit Surfaces and Radiance Fields for Multi-View Reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 5589–5599.Google ScholarCross Ref
37. Julian Ost, Fahim Mannan, Nils Thuerey, Julian Knodt, and Felix Heide. 2021. Neural Scene Graphs for Dynamic Scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2856–2865.Google ScholarCross Ref
38. Stefan Popov, Pablo Bauszat, and Vittorio Ferrari. 2020. CoReNet: Coherent 3D Scene Reconstruction from a Single RGB Image. In European Conference on Computer Vision. Springer, 366–383.Google ScholarDigital Library
39. Srikumar Ramalingam, Jaishanker K Pillai, Arpit Jain, and Yuichi Taguchi. 2013. Manhattan Junction Catalogue for Spatial Reasoning of Indoor Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 3065–3072.Google ScholarDigital Library
40. Erik Reinhard, Michael Adhikhmin, Bruce Gooch, and Peter Shirley. 2001. Color Transfer Between Images. IEEE Computer graphics and applications 21, 5 (2001), 34–41.Google ScholarDigital Library
41. Christian Reiser, Songyou Peng, Yiyi Liao, and Andreas Geiger. 2021. KiloNeRF: Speeding up Neural Radiance Fields with Thousands of Tiny MLPs. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 14335–14345.Google ScholarCross Ref
42. Gernot Riegler and Vladlen Koltun. 2020. Free View Synthesis. In European Conference on Computer Vision. Springer, 623–640.Google Scholar
43. Gernot Riegler and Vladlen Koltun. 2021. Stable View Synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12216–12225.Google ScholarCross Ref
44. Sara Fridovich-Keil and Alex Yu, Matthew Tancik, Qinhong Chen, Benjamin Recht, and Angjoo Kanazawa. 2022. Plenoxels: Radiance Fields without Neural Networks. In CVPR.Google Scholar
45. Paul-Edouard Sarlin, Cesar Cadena, Roland Siegwart, and Marcin Dymczyk. 2019. From Coarse to Fine: Robust Hierarchical Localization at Large Scale. In CVPR.Google Scholar
46. Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. 2020. SuperGlue: Learning Feature Matching with Graph Neural Networks. In CVPR.Google Scholar
47. Johannes L. Schönberger and Jan-Michael Frahm. 2016. Structure-from-Motion Revisited. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 4104–4113.Google Scholar
48. Bokui Shen, Fei Xia, Chengshu Li, Roberto Martín-Martín, Linxi Fan, Guanzhi Wang, Claudia Pérez-D’Arpino, Shyamal Buch, Sanjana Srivastava, Lyne Tchapmi, et al. 2020. iGibson 1.0: A Simulation Environment for Interactive Tasks in Large Realistic Scenes. In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 7520–7527.Google Scholar
49. Vincent Sitzmann, Justus Thies, Felix Heide, Matthias Nießner, Gordon Wetzstein, and Michael Zollhofer. 2019a. DeepVoxels: Learning Persistent 3D Feature Embeddings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2437–2446.Google ScholarCross Ref
50. Vincent Sitzmann, Michael Zollhöfer, and Gordon Wetzstein. 2019b. Scene Representation Networks: Continuous 3D-Structure-Aware Neural Scene Representations. In Proceedings of Advances in Neural Information Processing Systems. 1119–1130.Google Scholar
51. Shuran Song, Fisher Yu, Andy Zeng, Angel X Chang, Manolis Savva, and Thomas Funkhouser. 2017. Semantic Scene Completion from a Single Depth Image. In Proceedings of the IEEE conference on computer vision and pattern recognition. 1746–1754.Google ScholarCross Ref
52. Shuran Song, Linguang Zhang, and Jianxiong Xiao. 2015. Robot In a Room: Toward Perfect Object Recognition in Closed Environments. CoRR, abs/1507.02703 (2015).Google Scholar
53. Cheng Sun, Chi-Wei Hsiao, Min Sun, and Hwann-Tzong Chen. 2019. HorizonNet: Learning Room Layout With 1D Representation and Pano Stretch Data Augmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1047–1056.Google ScholarCross Ref
54. Richard Tucker and Noah Snavely. 2020. Single-View View Synthesis With Multiplane Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 551–560.Google ScholarCross Ref
55. Michael Waechter, Nils Moehrle, and Michael Goesele. 2014. Let There Be Color! — Large-Scale Texturing of 3D Reconstructions. In Proceedings of the European Conference on Computer Vision. Springer.Google ScholarCross Ref
56. Nanyang Wang, Yinda Zhang, Zhuwen Li, Yanwei Fu, Wei Liu, and Yu-Gang Jiang. 2018. Pixel2Mesh: Generating 3D Mesh Models from Single RGB Images. In Proceedings of the European Conference on Computer Vision (ECCV). 52–67.Google ScholarDigital Library
57. Peng Wang, Lingjie Liu, Yuan Liu, Christian Theobalt, Taku Komura, and Wenping Wang. 2021a. NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction. NeurIPS.Google Scholar
58. Qianqian Wang, Zhicheng Wang, Kyle Genova, Pratul P Srinivasan, Howard Zhou, Jonathan T Barron, Ricardo Martin-Brualla, Noah Snavely, and Thomas Funkhouser. 2021b. IBRNet: Learning Multi-View Image-Based Rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4690–4699.Google ScholarCross Ref
59. Chenggang Yan, Biyao Shao, Hao Zhao, Ruixin Ning, Yongdong Zhang, and Feng Xu. 2020. 3D Room Layout Estimation From a Single RGB Image. IEEE Transactions on Multimedia 22, 11 (2020), 3014–3024.Google ScholarCross Ref
60. Bangbang Yang, Yinda Zhang, Yinghao Xu, Yijin Li, Han Zhou, Hujun Bao, Guofeng Zhang, and Zhaopeng Cui. 2021. Learning Object-Compositional Neural Radiance Field for Editable Scene Rendering. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 13779–13788.Google ScholarCross Ref
61. Hao Yang and Hui Zhang. 2016. Efficient 3D Room Shape Recovery from a Single Panorama. In Proceedings of the IEEE conference on computer vision and pattern recognition. 5422–5430.Google ScholarCross Ref
62. Shang-Ta Yang, Fu-En Wang, Chi-Han Peng, Peter Wonka, Min Sun, and Hung-Kuo Chu. 2019. DuLa-Net: A Dual-Projection Network for Estimating Room Layouts From a Single RGB Panorama. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3363–3372.Google ScholarCross Ref
63. Lior Yariv, Jiatao Gu, Yoni Kasten, and Yaron Lipman. 2021. Volume Rendering of Neural Implicit Surfaces. Advances in Neural Information Processing Systems 34.Google Scholar
64. Lin Yen-Chen, Pete Florence, Jonathan T Barron, Alberto Rodriguez, Phillip Isola, and Tsung-Yi Lin. 2021. iNeRF: Inverting Neural Radiance Fields for Pose Estimation. In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 1323–1330.Google ScholarDigital Library
65. Alex Yu, Vickie Ye, Matthew Tancik, and Angjoo Kanazawa. 2021. pixelNeRF: Neural Radiance Fields From One or Few Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4578–4587.Google ScholarCross Ref
66. Greg Zaal, Sergej Majboroda, and Andreas Mischok. 2020. Poly Haven. https://polyhaven.com/. Accessed: 2022-05-03.Google Scholar
67. Xiaohang Zhan, Xingang Pan, Bo Dai, Ziwei Liu, Dahua Lin, and Chen Change Loy. 2020. Self-Supervised Scene De-Occlusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3784–3792.Google ScholarCross Ref
68. Cheng Zhang, Zhaopeng Cui, Cai Chen, Shuaicheng Liu, Bing Zeng, Hujun Bao, and Yinda Zhang. 2021a. DeepPanoContext: Panoramic 3D Scene Understanding With Holistic Scene Context Graph and Relation-Based Optimization. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 12632–12641.Google ScholarCross Ref
69. Cheng Zhang, Zhaopeng Cui, Yinda Zhang, Bing Zeng, Marc Pollefeys, and Shuaicheng Liu. 2021b. Holistic 3D Scene Understanding from a Single Image with Implicit Representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8833–8842.Google ScholarCross Ref
70. Yinda Zhang, Mingru Bai, Pushmeet Kohli, Shahram Izadi, and Jianxiong Xiao. 2017. DeepContext: Context-Encoding Neural Pathways for 3D Holistic Scene Understanding. In Proceedings of the IEEE international conference on computer vision. 1192–1201.Google ScholarCross Ref
71. Yinda Zhang, Shuran Song, Ping Tan, and Jianxiong Xiao. 2014. PanoContext: A Whole-Room 3D Context Model for Panoramic Scene Understanding. In European conference on computer vision. Springer, 668–686.Google ScholarCross Ref
72. Yi Zhou, Connelly Barnes, Jingwan Lu, Jimei Yang, and Hao Li. 2019. On the Continuity of Rotation Representations in Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5745–5753.Google ScholarCross Ref
73. Chuhang Zou, Alex Colburn, Qi Shan, and Derek Hoiem. 2018. LayoutNet: Reconstructing the 3D Room Layout From a Single RGB Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2051–2059.Google ScholarCross Ref