
“LGTM: Local-to-Global Text-driven Human Motion Diffusion Model”
Conference:
Type(s):
Title:
- LGTM: Local-to-Global Text-driven Human Motion Diffusion Model
Presenter(s)/Author(s):
Abstract:
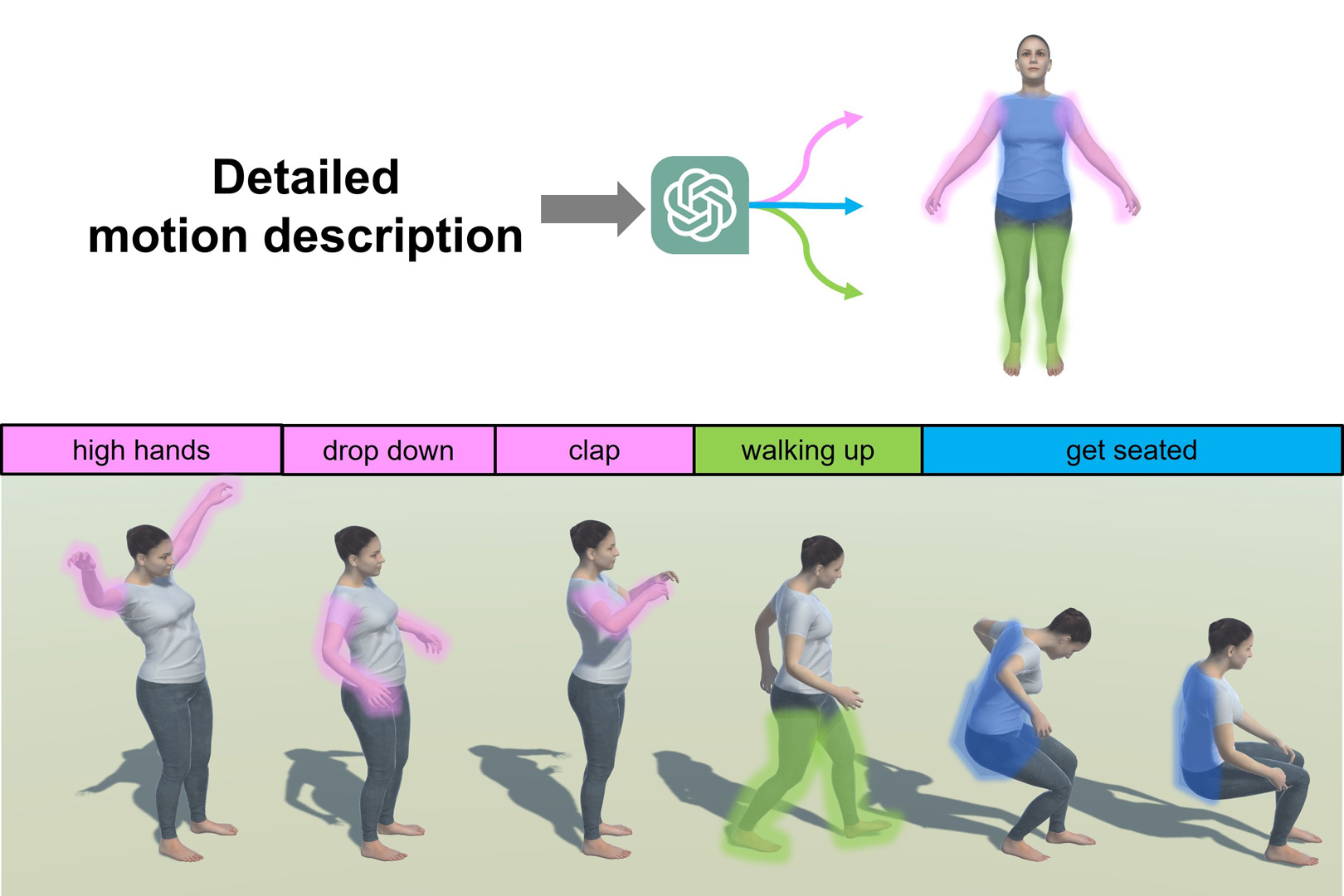
We introduce LGTM, a novel Local-to-Global pipeline for Text-to-Motion generation based on diffusion model. It decomposes motion description to body-part level with LLMs and encodes them with corresponding body part motion individually, then optimizes whole body motion by attention encoder. As a result, it can generate local semantics well-matched motion.
References:
[1]
Chaitanya Ahuja and Louis-Philippe Morency. 2019. Language2pose: Natural Language Grounded Pose Forecasting. In 2019 International Conference on 3D Vision (3DV). IEEE, 719?728.
[2]
Simon Alexanderson, Rajmund Nagy, Jonas Beskow, and Gustav Eje Henter. 2023. Listen, Denoise, Action! Audio-Driven Motion Synthesis with Diffusion Models. ACM Transactions on Graphics 42, 4 (Aug. 2023), 1?20. https://doi.org/10.1145/3592458
[3]
Nikos Athanasiou, Mathis Petrovich, Michael J. Black, and G?l Varol. 2022. TEACH: Temporal Action Composition for 3D Humans. In 2022 International Conference on 3D Vision (3DV). IEEE Computer Society, 414?423. https://doi.org/10.1109/3DV57658.2022.00053
[4]
Jinseok Bae, Jungdam Won, Donggeun Lim, Cheol-Hui Min, and Young Min Kim. 2023. PMP: Learning to Physically Interact with Environments Using Part-wise Motion Priors. In ACM SIGGRAPH 2023 Conference Proceedings(SIGGRAPH ?23). Association for Computing Machinery, New York, NY, USA, 1?10. https://doi.org/10.1145/3588432.3591487
[5]
Lu Chen, Sida Peng, and Xiaowei Zhou. 2021. Towards Efficient and Photorealistic 3D Human Reconstruction: A Brief Survey. Visual Informatics 5, 4 (Dec. 2021), 11?19. https://doi.org/10.1016/j.visinf.2021.10.003
[6]
Xin Chen, Biao Jiang, Wen Liu, Zilong Huang, Bin Fu, Tao Chen, and Gang Yu. 2023a. Executing Your Commands via Motion Diffusion in Latent Space. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Vancouver, BC, Canada, 18000?18010. https://doi.org/10.1109/CVPR52729.2023.01726
[7]
Xin Chen, Biao Jiang, Wen Liu, Zilong Huang, Bin Fu, Tao Chen, Jingyi Yu, and Gang Yu. 2023b. Executing Your Commands via Motion Diffusion in Latent Space. https://doi.org/10.48550/arXiv.2212.04048 arxiv:2212.04048 [cs]
[8]
Anindita Ghosh, Noshaba Cheema, Cennet Oguz, Christian Theobalt, and Philipp Slusallek. 2021. Synthesis of Compositional Animations From Textual Descriptions. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 1396?1406.
[9]
Anmol Gulati, James Qin, Chung-Cheng Chiu, Niki Parmar, Yu Zhang, Jiahui Yu, Wei Han, Shibo Wang, Zhengdong Zhang, Yonghui Wu, and Ruoming Pang. 2020. Conformer: Convolution-augmented Transformer for Speech Recognition. arxiv:2005.08100 [cs, eess]
[10]
Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. 2022a. Generating Diverse and Natural 3D Human Motions From Text. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5152?5161.
[11]
Chuan Guo, Xinxin Zuo, Sen Wang, and Li Cheng. 2022b. TM2T: Stochastic and Tokenized Modeling for the Reciprocal Generation of 3D Human Motions and Texts. In Computer Vision ? ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23?27, 2022, Proceedings, Part XXXV. Springer-Verlag, Berlin, Heidelberg, 580?597. https://doi.org/10.1007/978-3-031-19833-5_34
[12]
Chris Hecker, Bernd Raabe, Ryan W. Enslow, John DeWeese, Jordan Maynard, and Kees van Prooijen. 2008. Real-Time Motion Retargeting to Highly Varied User-Created Morphologies. ACM Transactions on Graphics 27, 3 (Aug. 2008), 1?11. https://doi.org/10.1145/1360612.1360626
[13]
Deok-Kyeong Jang, Soomin Park, and Sung-Hee Lee. 2022. Motion Puzzle: Arbitrary Motion Style Transfer by Body Part. ACM Transactions on Graphics (Jan. 2022). https://doi.org/10.1145/3516429
[14]
Won-Seob Jang, Won-Kyu Lee, In-Kwon Lee, and Jehee Lee. 2008. Enriching a Motion Database by Analogous Combination of Partial Human Motions. The Visual Computer 24, 4 (April 2008), 271?280. https://doi.org/10.1007/s00371-007-0200-1
[15]
Biao Jiang, Xin Chen, Wen Liu, Jingyi Yu, Gang Yu, and Tao Chen. 2023. MotionGPT: Human Motion as a Foreign Language. https://doi.org/10.48550/arXiv.2306.14795 arxiv:2306.14795 [cs]
[16]
Chong Lan, Yongsheng Wang, Chengze Wang, Shirong Song, and Zheng Gong. 2023. Application of ChatGPT-Based Digital Human in Animation Creation. Future Internet 15, 9 (Sept. 2023), 300. https://doi.org/10.3390/fi15090300
[17]
Seyoung Lee, Jiye Lee, and Jehee Lee. 2022. Learning Virtual Chimeras by Dynamic Motion Reassembly. ACM Transactions on Graphics 41, 6 (Nov. 2022), 182:1?182:13. https://doi.org/10.1145/3550454.3555489
[18]
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J. Black. 2015. SMPL: A Skinned Multi-Person Linear Model. ACM Transactions on Graphics 34, 6 (Oct. 2015), 248:1?248:16. https://doi.org/10.1145/2816795.2818013
[19]
Mathis Petrovich, Michael J. Black, and G?l Varol. 2022. TEMOS: Generating Diverse Human Motions from Textual Descriptions. In Computer Vision ? ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23?27, 2022, Proceedings, Part XXII. Springer-Verlag, Berlin, Heidelberg, 480?497. https://doi.org/10.1007/978-3-031-20047-2_28
[20]
Mathis Petrovich, Michael J. Black, and G?l Varol. 2023. TMR: Text-to-Motion Retrieval Using Contrastive 3D Human Motion Synthesis. arxiv:2305.00976 [cs]
[21]
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. 2022. DreamFusion: Text-to-3D Using 2D Diffusion. https://doi.org/10.48550/arXiv.2209.14988 arxiv:2209.14988 [cs, stat]
[22]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. https://doi.org/10.48550/arXiv.2103.00020 arxiv:2103.00020 [cs]
[23]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bjorn Ommer. 2022. High-Resolution Image Synthesis with Latent Diffusion Models. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, New Orleans, LA, USA, 10674?10685. https://doi.org/10.1109/CVPR52688.2022.01042
[24]
Mark Scanlon, Frank Breitinger, Christopher Hargreaves, Jan-Niclas Hilgert, and John Sheppard. 2023. ChatGPT for Digital Forensic Investigation: The Good, the Bad, and the Unknown. Forensic Science International: Digital Investigation 46 (Oct. 2023), 301609. https://doi.org/10.1016/j.fsidi.2023.301609
[25]
Asako Soga, Yuho Yazaki, Bin Umino, and Motoko Hirayama. 2016. Body-Part Motion Synthesis System for Contemporary Dance Creation. In ACM SIGGRAPH 2016 Posters. ACM, Anaheim California, 1?2. https://doi.org/10.1145/2945078.2945107
[26]
Jiaming Song, Chenlin Meng, and Stefano Ermon. 2022. Denoising Diffusion Implicit Models. https://doi.org/10.48550/arXiv.2010.02502 arxiv:2010.02502 [cs]
[27]
Sebastian Starke, He Zhang, Taku Komura, and Jun Saito. 2019. Neural State Machine for Character-Scene Interactions. ACM Transactions on Graphics 38, 6 (Nov. 2019), 209:1?209:14. https://doi.org/10.1145/3355089.3356505
[28]
Sebastian Starke, Yiwei Zhao, Taku Komura, and Kazi Zaman. 2020. Local Motion Phases for Learning Multi-Contact Character Movements. ACM Transactions on Graphics 39, 4 (July 2020), 54:1?54:13. https://doi.org/10.1145/3386569.3392450
[29]
Sebastian Starke, Yiwei Zhao, Fabio Zinno, and Taku Komura. 2021. Neural Animation Layering for Synthesizing Martial Arts Movements. ACM Transactions on Graphics 40, 4 (July 2021), 92:1?92:16. https://doi.org/10.1145/3450626.3459881
[30]
Guy Tevet, Brian Gordon, Amir Hertz, Amit H. Bermano, and Daniel Cohen-Or. 2022a. MotionCLIP: Exposing Human Motion Generation to CLIP Space. In Computer Vision ? ECCV 2022(Lecture Notes in Computer Science), Shai Avidan, Gabriel Brostow, Moustapha Ciss?, Giovanni Maria Farinella, and Tal Hassner (Eds.). Springer Nature Switzerland, Cham, 358?374. https://doi.org/10.1007/978-3-031-20047-2_21
[31]
Guy Tevet, Sigal Raab, Brian Gordon, Yoni Shafir, Daniel Cohen-or, and Amit Haim Bermano. 2022b. Human Motion Diffusion Model. In The Eleventh International Conference on Learning Representations.
[32]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ?ukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. In Advances in Neural Information Processing Systems, Vol. 30. Curran Associates, Inc.
[33]
Heyuan Yao, Zhenhua Song, Yuyang Zhou, Tenglong Ao, Baoquan Chen, and Libin Liu. [n. d.]. MoConVQ: Unified Physics-Based Motion Control via Scalable Discrete Representations. ([n. d.]).
[34]
Ye Yuan, Jiaming Song, Umar Iqbal, Arash Vahdat, and Jan Kautz. 2022. PhysDiff: Physics-Guided Human Motion Diffusion Model. https://doi.org/10.48550/arXiv.2212.02500 arxiv:2212.02500 [cs]
[35]
Ailing Zeng, Lei Yang, Xuan Ju, Jiefeng Li, Jianyi Wang, and Qiang Xu. 2022. SmoothNet: A Plug-and-Play Network for Refining Human Poses in Videos. In European Conference on Computer Vision. Springer.
[36]
He Zhang, Sebastian Starke, Taku Komura, and Jun Saito. 2018. Mode-Adaptive Neural Networks for Quadruped Motion Control. ACM Transactions on Graphics 37, 4 (July 2018), 145:1?145:11. https://doi.org/10.1145/3197517.3201366
[37]
Mingyuan Zhang, Zhongang Cai, Liang Pan, Fangzhou Hong, Xinying Guo, Lei Yang, and Ziwei Liu. 2022. MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model. arxiv:2208.15001 [cs]
[38]
Yuheng Zhao, Jinjing Jiang, Yi Chen, Richen Liu, Yalong Yang, Xiangyang Xue, and Siming Chen. 2022. Metaverse: Perspectives from Graphics, Interactions and Visualization. Visual Informatics 6, 1 (March 2022), 56?67. https://doi.org/10.1016/j.visinf.2022.03.002