
“Global-to-local generative model for 3D shapes”
Conference:
Type(s):
Title:
- Global-to-local generative model for 3D shapes
Session/Category Title:
- Geometry generation
Presenter(s)/Author(s):
Moderator(s):
Abstract:
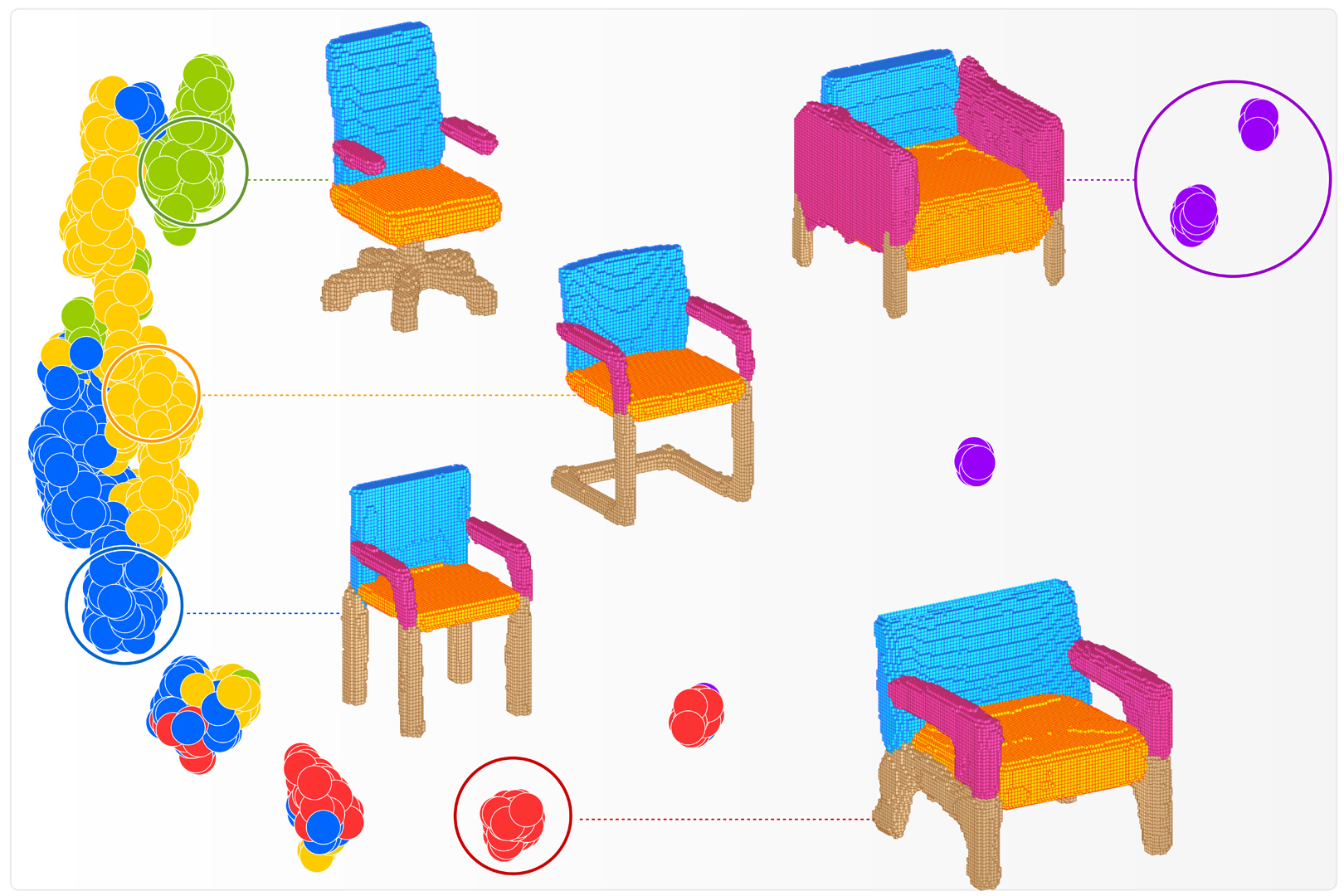
We introduce a generative model for 3D man-made shapes. The presented method takes a global-to-local (G2L) approach. An adversarial network (GAN) is built first to construct the overall structure of the shape, segmented and labeled into parts. A novel conditional auto-encoder (AE) is then augmented to act as a part-level refiner. The GAN, associated with additional local discriminators and quality losses, synthesizes a voxel-based model, and assigns the voxels with part labels that are represented in separate channels. The AE is trained to amend the initial synthesis of the parts, yielding more plausible part geometries. We also introduce new means to measure and evaluate the performance of an adversarial generative model. We demonstrate that our global-to-local generative model produces significantly better results than a plain three-dimensional GAN, in terms of both their shape variety and the distribution with respect to the training data.
References:
1. Sanjeev Arora, Rong Ge, Yingyu Liang, Tengyu Ma, and Yi Zhang. 2017. Generalization and Equilibrium in Generative Adversarial Nets (GANs). In Proc. Int. Conf. on Machine Learning, Vol. 70. 224–232.Google Scholar
2. David Berthelot, Thomas Schumm, and Luke Metz. 2017. BEGAN: boundaryequilibrium generative adversarial networks. arXiv preprint arXiv:1703.10717 (2017).Google Scholar
3. Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, and others. 2015. Shapenet: An information-rich 3D model repository. arXiv preprint arXiv:1512.03012 (2015).Google Scholar
4. Siddhartha Chaudhuri, Evangelos Kalogerakis, Leonidas Guibas, and Vladlen Koltun. 2011. Probabilistic Reasoning for Assembly-based 3D Modeling. ACM Trans. on Graphics 30, 4 (2011), 35:1–35:10. Google ScholarDigital Library
5. Siddhartha Chaudhuri and Vladlen Koltun. 2010. Data-driven Suggestions for Creativity Support in 3D Modeling. ACM Trans. on Graphics 29, 6 (2010), 183:1–183:10. Google ScholarDigital Library
6. Ishan Durugkar, Ian Gemp, and Sridhar Mahadevan. 2016. Generative multi-adversarial networks. arXiv preprint arXiv:1611.01673 (2016).Google Scholar
7. Haoqiang Fan, Hao Su, and Leonidas J Guibas. 2017. A Point Set Generation Network for 3D Object Reconstruction From a Single Image. In Proc. IEEE Conf. on Computer Vision & Pattern Recognition. 605–613.Google ScholarCross Ref
8. Noa Fish, Melinos Averkiou, Oliver van Kaick, Olga Sorkine-Hornung, Daniel Cohen-Or, and Niloy J. Mitra. 2014. Meta-representation of Shape Families. ACM Trans. on Graphics 33, 4 (2014), 34:1–34:11. Google ScholarDigital Library
9. Thomas Funkhouser, Michael Kazhdan, Philip Shilane, Patrick Min, William Kiefer, Ayellet Tal, Szymon Rusinkiewicz, and David Dobkin. 2004. Modeling by Example. ACM Trans. on Graphics 23, 3 (2004), 652–663. Google ScholarDigital Library
10. Rohit Girdhar, David F Fouhey, Mikel Rodriguez, and Abhinav Gupta. 2016. Learning a predictable and generative vector representation for objects. In Proc. Euro. Conf. on Computer Vision. 484–499.Google ScholarCross Ref
11. Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative Adversarial Nets. In Advances in Neural Information Processing Systems (NIPS). 2672–2680. Google ScholarDigital Library
12. Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, and Aaron C Courville. 2017. Improved training of wasserstein gans. In Advances in Neural Information Processing Systems (NIPS). 5769–5779. Google ScholarDigital Library
13. Quan Hoang, Tu Dinh Nguyen, Trung Le, and Dinh Phung. 2017. Multi-Generator Gernerative Adversarial Nets. arXiv preprint arXiv:1708.02556 (2017).Google Scholar
14. Haibin Huang, Evangelos Kalogerakis, and Benjamin Marlin. 2015. Analysis and Synthesis of 3D Shape Families via Deep-learned Generative Models of Surfaces. Computer Graphics Forum 34, 5 (2015), 25–38.Google ScholarCross Ref
15. Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa. 2017. Globally and Locally Consistent Image Completion. ACM Trans. on Graphics 36, 4 (2017), 107:1–107:14. Google ScholarDigital Library
16. Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. 2017. Image-to-Image Translation with Conditional Adversarial Networks. Proc. IEEE Conf. on Computer Vision & Pattern Recognition (2017), 5967–5976.Google Scholar
17. Evangelos Kalogerakis, Siddhartha Chaudhuri, Daphne Koller, and Vladlen Koltun. 2012. A Probabilistic Model for Component-based Shape Synthesis. ACM Trans. on Graphics 31, 4 (2012), 55:1–55:11. Google ScholarDigital Library
18. Vladimir G. Kim, Wilmot Li, Niloy J. Mitra, Siddhartha Chaudhuri, Stephen DiVerdi, and Thomas Funkhouser. 2013. Learning Part-based Templates from Large Collections of 3D Shapes. ACM Trans. on Graphics 32, 4 (2013), 70:1–70:12. Google ScholarDigital Library
19. Diederik P Kingma and Max Welling. 2014. Auto-Encoding Variational Bayes. In Proc. Int. Conf. on Learning Representations.Google Scholar
20. Jun Li, Kai Xu, Siddhartha Chaudhuri, Ersin Yumer, Hao Zhang, and Leonidas Guibas. 2017. GRASS: Generative Recursive Autoencoders for Shape Structures. ACM Trans. on Graphics 36, 4 (2017), 52:1–52:14. Google ScholarDigital Library
21. Chen-Hsuan Lin, Chen Kong, and Simon Lucey. 2018. Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction. In AAAI Conference on Artificial Intelligence (AAAI).Google Scholar
22. Guilin Liu, Fitsum A Reda, Kevin J Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro. 2018. Image Inpainting for Irregular Holes Using Partial Convolutions. arXiv preprint arXiv:1804.07723 (2018).Google Scholar
23. Jerry Liu, Fisher Yu, and Thomas Funkhouser. 2017. Interactive 3D modeling with a generative adversarial network. In Proc. Int. Conf. on 3D Vision. 126–134.Google ScholarCross Ref
24. Niloy Mitra, Michael Wand, Hao (Richard) Zhang, Daniel Cohen-Or, Vladimir Kim, and Qi-Xing Huang. 2013. Structure-aware Shape Processing. In SIGGRAPH Asia 2013 Courses. 1:1–1:20. Google ScholarDigital Library
25. C. Nash and C. K. I. Williams. 2017. The Shape Variational Autoencoder: A Deep Generative Model of Part-segmented 3D Objects. Computer Graphics Forum 36, 5 (2017), 1–12. Google ScholarDigital Library
26. Tu Nguyen, Trung Le, Hung Vu, and Dinh Phung. 2017. Dual discriminator generative adversarial nets. In Advances in Neural Information Processing Systems (NIPS). 2667–2677. Google ScholarDigital Library
27. Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. 2017. Pointnet: Deep learning on point sets for 3D classification and segmentation. Proc. IEEE Conf. on Computer Vision & Pattern Recognition (2017), 652–660.Google Scholar
28. Alec Radford, Luke Metz, and Soumith Chintala. 2015. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434 (2015).Google Scholar
29. Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. 2016a. Improved Techniques for Training (GANs). In Advances in Neural Information Processing Systems (NIPS). 2234–2242. Google ScholarDigital Library
30. Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. 2016b. Improved Techniques for Training (GANs). In Advances in Neural Information Processing Systems (NIPS). 2234–2242. Google ScholarDigital Library
31. Tianjia Shao, Yin Yang, Yanlin Weng, Qiming Hou, and Kun Zhou. 2018. H-CNN: Spatial Hashing Based CNN for 3D Shape Analysis. arXiv preprint arXiv:1803.11385 (2018).Google Scholar
32. Robert W. Sumner, Johannes Schmid, and Mark Pauly. 2007. Embedded Deformation for Shape Manipulation. ACM Trans. on Graphics 26, 3 (2007), 80:1–80:7. Google ScholarDigital Library
33. Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. 2016. Rethinking the inception architecture for computer vision. In Proc. IEEE Conf. on Computer Vision & Pattern Recognition. 2818–2826.Google ScholarCross Ref
34. Jerry Talton, Lingfeng Yang, Ranjitha Kumar, Maxine Lim, Noah Goodman, and Radomír Měch. 2012. Learning Design Patterns with Bayesian Grammar Induction. In Proc. ACM Symp. on User Interface Software and Technology. 63–74. Google ScholarDigital Library
35. Maxim Tatarchenko, Alexey Dosovitskiy, and Thomas Brox. 2017. Octree generating networks: Efficient convolutional architectures for high-resolution 3D outputs. In Proc. Int. Conf. on Computer Vision. 2088–2096.Google ScholarCross Ref
36. Xiaolong Wang and Abhinav Gupta. 2016. Generative image modeling using style and structure adversarial networks. In Proc. Euro. Conf. on Computer Vision. 318–335.Google ScholarCross Ref
37. Jiajun Wu, Yifan Wang, Tianfan Xue, Xingyuan Sun, Bill Freeman, and Josh Tenenbaum. 2017. Marrnet: 3D shape reconstruction via 2.5D sketches. In Advances in Neural Information Processing Systems (NIPS). 540–550. Google ScholarDigital Library
38. Jiajun Wu, Chengkai Zhang, Tianfan Xue, William T. Freeman, and Joshua B. Tenenbaum. 2016. Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-adversarial Modeling. In Advances in Neural Information Processing Systems (NIPS). 82–90. Google ScholarDigital Library
39. Zhirong Wu, Shuran Song, Aditya Khosla, Fisher Yu, Linguang Zhang, Xiaoou Tang, and Jianxiong Xiao. 2015. 3d shapenets: A deep representation for volumetric shapes. In Proc. IEEE Conf. on Computer Vision & Pattern Recognition. 1912–1920.Google Scholar
40. Kai Xu, Hao Zhang, Daniel Cohen-Or, and Baoquan Chen. 2012. Fit and Diverse: Set Evolution for Inspiring 3D Shape Galleries. ACM Trans. on Graphics 31, 4 (2012), 57:1–57:10. Google ScholarDigital Library
41. Xinchen Yan, Jimei Yang, Kihyuk Sohn, and Honglak Lee. 2016. Attribute2image: Conditional image generation from visual attributes. In Proc. Euro. Conf. on Computer Vision. 776–791.Google ScholarCross Ref
42. Li Yi, Vladimir G. Kim, Duygu Ceylan, I-Chao Shen, Mengyan Yan, Hao Su, Cewu Lu, Qixing Huang, Alla Sheffer, and Leonidas Guibas. 2016. A Scalable Active Framework for Region Annotation in 3D Shape Collections. ACM Trans. on Graphics 35, 6 (2016), 210:1–210:12. Google ScholarDigital Library
43. Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S. Huang. 2018. Generative Image Inpainting With Contextual Attention. In Proc. IEEE Conf. on Computer Vision & Pattern Recognition. 5505–5514.Google Scholar
44. Jun-Yan Zhu, Philipp Krähenbühl, Eli Shechtman, and Alexei A Efros. 2016. Generative visual manipulation on the natural image manifold. In Proc. Euro. Conf. on Computer Vision. 597–613.Google ScholarCross Ref