
“Fast parallel surface and solid voxelization on GPUs”
Conference:
Type(s):
Title:
- Fast parallel surface and solid voxelization on GPUs
Session/Category Title:
- Volumetric modeling and rendering
Presenter(s)/Author(s):
Moderator(s):
Abstract:
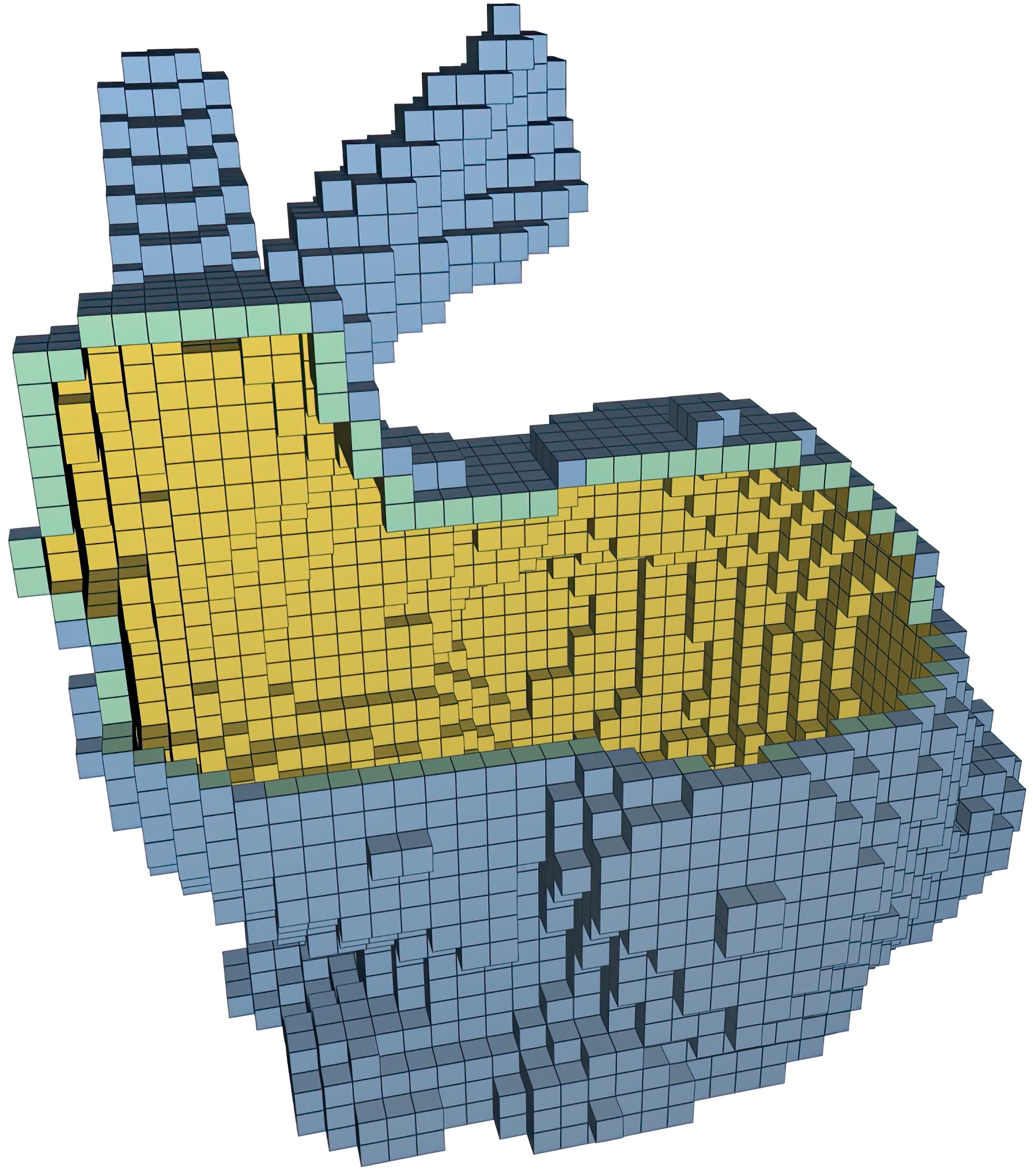
This paper presents data-parallel algorithms for surface and solid voxelization on graphics hardware. First, a novel conservative surface voxelization technique, setting all voxels overlapped by a mesh’s triangles, is introduced, which is up to one order of magnitude faster than previous solutions leveraging the standard rasterization pipeline. We then show how the involved new triangle/box overlap test can be adapted to yield a 6-separating surface voxelization, which is thinner but still connected and gap-free. Complementing these algorithms, both a triangle-parallel and a tile-based technique for solid voxelization are subsequently presented. Finally, addressing the high memory consumption of high-resolution voxel grids, we introduce a novel octree-based sparse solid voxelization approach, where only close to the solid’s boundary finest-level voxels are stored, whereas uniform interior and exterior regions are represented by coarser-level voxels. This representation is created directly from a mesh without requiring a full intermediate solid voxelization, enabling GPU-based voxelizations of unprecedented size.
References:
1. Abrash, M. 2009. Rasterization on Larrabee. Dr. Dobb’s. http://www.drdobbs.com/high-performance-computing/217200602.Google Scholar
2. Aila, T., and Laine, S. 2009. Understanding the efficiency of ray traversal on GPUs. In Proceedings of High Performance Graphics 2009, 145–149. Google ScholarDigital Library
3. Akenine-Möller, T., and Aila, T. 2005. Conservative and tiled rasterization using a modified triangle set-up. Journal of Graphics Tools 10, 3, 1–8.Google ScholarCross Ref
4. Akenine-Möller, T. 2001. Fast 3D triangle-box overlap testing. Journal of Graphics Tools 6, 1, 29–33. Google ScholarDigital Library
5. Billeter, M., Olsson, O., and Assarsson, U. 2009. Efficient stream compaction on wide SIMD many-core architectures. In Proceedings of High Performance Graphics 2009, 159–166. Google ScholarDigital Library
6. Cohen-Or, D., and Kaufman, A. 1995. Fundamentals of surface voxelization. Graphical Models and Image Processing 57, 6, 453–461. Google ScholarDigital Library
7. Dong, Z., Chen, W., Bao, H., Zhang, H., and Peng, Q. 2004. Real-time voxelization for complex models. In Proceedings of Pacific Graphics 2004, 43–50. Google ScholarDigital Library
8. Eisemann, E., and Décoret, X. 2006. Fast scene voxelization and applications. In Proceedings of ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games 2006, 71–78. Google ScholarDigital Library
9. Eisemann, E., and Décoret, X. 2008. Single-pass GPU solid voxelization for real-time applications. In Proceedings of Graphics Interface 2008, 73–80. Google ScholarDigital Library
10. Eisenacher, C., and Loop, C. 2010. Data-parallel micropolygon rasterization. In Eurographics 2010 Short Papers, 53–56.Google Scholar
11. Fang, S., and Chen, H. 2000. Hardware accelerated voxelization. Computers & Graphics 24, 3, 433–442.Google Scholar
12. Fatahalian, K., Luong, E., Boulos, S., Akeley, K., Mark, W. R., and Hanrahan, P. 2009. Data-parallel rasterization of micropolygons with defocus and motion blur. In Proceedings of High Performance Graphics 2009, 59–68. Google ScholarDigital Library
13. Haines, E. A., and Wallace, J. R. 1991. Shaft culling for efficient ray-cast radiosity. In Proceedings of Eurographics Workshop on Rendering 1991, 122–138.Google Scholar
14. Hasselgren, J., Akenine-Möller, T., and Ohlsson, L. 2005. Conservative rasterization. In GPU Gems 2, M. Pharr, Ed. Addison Wesley Professional, ch. 42, 677–690.Google Scholar
15. Huang, J., Yagel, R., Filippov, V., and Kurzion, Y. 1998. An accurate method for voxelizing polygon meshes. In Proceedings of IEEE Symposium on Volume Visualization 1998, 119–126. Google ScholarDigital Library
16. Ivson, P., Duarte, L., and Celes, W. 2009. GPU-accelerated uniform grid construction for ray tracing dynamic scenes. Tech. Rep. 14/09, Pontifícia Universidade Católica do Rio de Janeiro.Google Scholar
17. Kalojanov, J., and Slusallek, P. 2009. A parallel algorithm for construction of uniform grids. In Proceedings of High Performance Graphics 2009, 23–28. Google ScholarDigital Library
18. Khronos OpenCL Working Group. 2010. The OpenCL Specification. Version: 1.1.Google Scholar
19. Lauterbach, C., Garland, M., Sengupta, S., Luebke, D., and Manocha, D. 2009. Fast BVH construction on GPUs. Computer Graphics Forum 28, 2, 375–384.Google ScholarCross Ref
20. Li, W., Fan, Z., Wei, X., and Kaufman, A. 2005. Flow simulation with complex boundaries. In GPU Gems 2, M. Pharr, Ed. Addison Wesley Professional, ch. 47, 747–764.Google Scholar
21. Liu, F., Huang, M.-C., Liu, X.-H., and Wu, E.-H. 2010. FreePipe: a programmable parallel rendering architecture for efficient multifragment effects. In Proceedings of ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games 2010, 75–82. Google ScholarDigital Library
22. Merrill, D., and Grimshaw, A. 2010. Revisiting sorting for GPGPU stream architectures. Tech. Rep. CS2010-03, Department of Computer Science, University of Virginia.Google Scholar
23. Nichols, G., Penmatsa, R., and Wyman, C. 2010. Interactive, multiresolution image-space rendering for dynamic area lighting. Computer Graphics Forum 29, 4, 1279–1288. Google ScholarDigital Library
24. Pineda, J. 1988. A parallel algorithm for polygon rasterization. Computer Graphics (Proceedings of SIGGRAPH 88) 22, 4, 17–20. Google ScholarDigital Library
25. Reinbothe, C. K., Boubekeur, T., and Alexa, M. 2009. Hybrid ambient occlusion. In Eurographics 2009 Annex (Areas Papers), 51–57.Google Scholar
26. Satish, N., Harris, M., and Garland, M. 2009. Designing efficient sorting algorithms for manycore GPUs. In Proceedings of IEEE International Parallel & Distributed Processing Symposium 2009, 1–10. Google ScholarDigital Library
27. Seiler, L., Carmean, D., Sprangle, E., Forsyth, T., Abrash, M., Dubey, P., Junkins, S., Lake, A., Sugerman, J., Cavin, R., Espasa, R., Grochowski, E., Juan, T., and Hanrahan, P. 2008. Larrabee: A many-core x86 architecture for visual computing. ACM Transactions on Graphics 27, 3, 18:1–18:15. Google ScholarDigital Library
28. Sun, X., Zhou, K., Stollnitz, E., Shi, J., and Guo, B. 2008. Interactive relighting of dynamic refractive objects. ACM Transactions on Graphics 27, 3, 35:1–35:9. Google ScholarDigital Library
29. Zhang, L., Chen, W., Ebert, D. S., and Peng, Q. 2007. Conservative voxelization. The Visual Computer 23, 9–11, 783–792. Google ScholarDigital Library
30. Zhou, K., Hou, Q., Wang, R., and Guo, B. 2008. Real-time KD-tree construction on graphics hardware. ACM Transactions on Graphics 27, 5, 126:1–126:9. Google ScholarDigital Library
31. Zhou, K., Gong, M., Huang, X., and Guo, B. 2010. Data-parallel octrees for surface reconstruction. IEEE Transactions on Visualization and Computer Graphics. To appear. Google ScholarDigital Library