
“DreamFont3D: Personalized Text-to-3D Artistic Font Generation” by Li, Meng, Wu, Li and Meng
Conference:
Type(s):
Title:
- DreamFont3D: Personalized Text-to-3D Artistic Font Generation
Presenter(s)/Author(s):
Abstract:
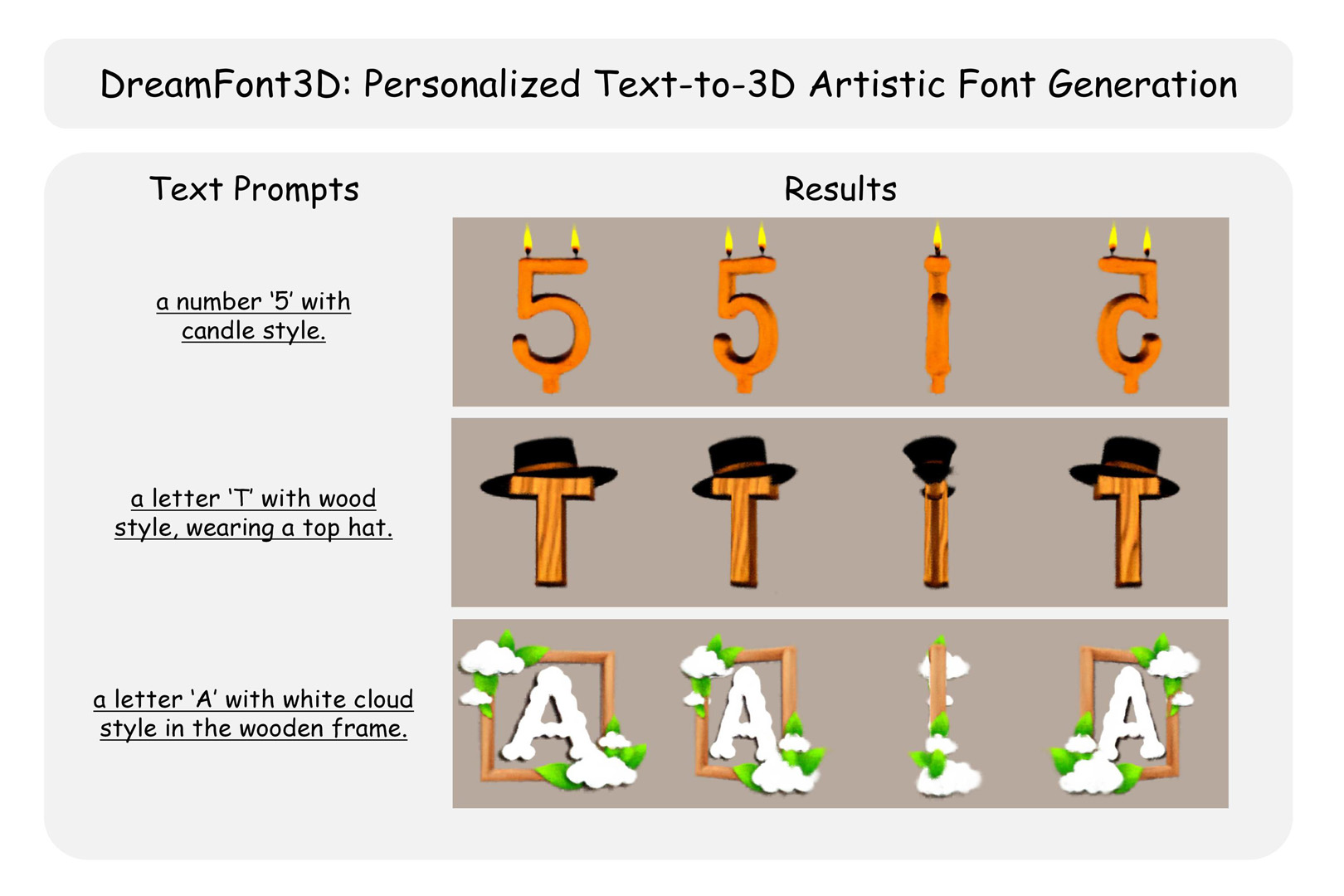
This paper presents a novel text-to-3D font generation model. It allows text prompt to describe 3D font styles, and script-generated font masks or hand-drawn font layouts to constrain the 3D font structure at multi-views, achieving stunning 3D representation of artistic font and the control of local effects.
References:
[1]
Omer Bar-Tal, Lior Yariv, Yaron Lipman, and Tali Dekel. 2023. MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation. In Proceedings of the 40th International Conference on Machine Learning(ICML?23). Article 74, 16 pages.
[2]
Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, 2015. Shapenet: An information-rich 3d model repository. arXiv preprint arXiv:1512.03012 (2015).
[3]
Hila Chefer, Yuval Alaluf, Yael Vinker, Lior Wolf, and Daniel Cohen-Or. 2023. Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models. ACM Transactions on Graphics (TOG) 42, 4 (2023), 1?10.
[4]
Rui Chen, Yongwei Chen, Ningxin Jiao, and Kui Jia. 2023a. Fantasia3D: Disentangling Geometry and Appearance for High-quality Text-to-3D Content Creation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV).
[5]
Yang Chen, Yingwei Pan, Yehao Li, Ting Yao, and Tao Mei. 2023b. Control3d: Towards controllable text-to-3d generation. In Proceedings of the 31st ACM International Conference on Multimedia. 1148?1156.
[6]
DeepFloyd. 2022. DeepFloyd IF. https://github.com/deep-floyd/IF.
[7]
Pei Dong, Lei Wu, Lei Meng, and Xiangxu Meng. 2022. Hr-prgan: High-resolution story visualization with progressive generative adversarial networks. Information Sciences 614 (2022), 548?562.
[8]
Dave Epstein, Allan Jabri, Ben Poole, Alexei A. Efros, and Aleksander Holynski. 2023. Diffusion Self-Guidance for Controllable Image Generation. (2023).
[9]
Rinon Gal, Moab Arar, Yuval Atzmon, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. 2023. Encoder-based domain tuning for fast personalization of text-to-image models. ACM Transactions on Graphics (TOG) 42, 4 (2023), 1?13.
[10]
Yue Gao, Yuan Guo, Zhouhui Lian, Yingmin Tang, and Jianguo Xiao. 2019. Artistic glyph image synthesis via one-stage few-shot learning. ACM Transactions on Graphics (TOG) 38, 6 (2019), 1?12.
[11]
Wenya Guo, Ying Zhang, Xiangrui Cai, Lei Meng, Jufeng Yang, and Xiaojie Yuan. 2020. LD-MAN: Layout-driven multimodal attention network for online news sentiment recognition. IEEE Transactions on Multimedia 23 (2020), 1785?1798.
[12]
Yuze He, Yushi Bai, Matthieu Lin, Wang Zhao, Yubin Hu, Jenny Sheng, Ran Yi, Juanzi Li, and Yong-Jin Liu. 2023a. T3Bench: Benchmarking Current Progress in Text-to-3D Generation. arxiv:2310.02977 [cs.CV]
[13]
Yutong He, Ruslan Salakhutdinov, and J. Zico Kolter. 2023b. Localized Text-to-Image Generation for Free via Cross Attention Control. arxiv:2306.14636 [cs.CV]
[14]
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-or. 2023. Prompt-to-Prompt Image Editing with Cross-Attention Control. In The Eleventh International Conference on Learning Representations.
[15]
Ajay Jain, Ben Mildenhall, Jonathan T Barron, Pieter Abbeel, and Ben Poole. 2022. Zero-shot text-guided object generation with dream fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 867?876.
[16]
Yue Jiang, Zhouhui Lian, Yingmin Tang, and Jianguo Xiao. 2017. DCFont: an end-to-end deep chinese font generation system. SIGGRAPH Asia 2017 Technical Briefs (2017).
[17]
Tero Karras, Miika Aittala, Samuli Laine, Erik H?rk?nen, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2021. Alias-free generative adversarial networks. Advances in neural information processing systems 34 (2021), 852?863.
[18]
Yunji Kim, Jiyoung Lee, Jin-Hwa Kim, Jung-Woo Ha, and Jun-Yan Zhu. 2023. Dense text-to-image generation with attention modulation. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 7701?7711.
[19]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. 2022a. BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation. In ICML.
[20]
Wei Li, Yongxing He, Yanwei Qi, Zejian Li, and Yongchuan Tang. 2020. FET-GAN: Font and effect transfer via k-shot adaptive instance normalization. In Proceedings of the AAAI conference on artificial intelligence, Vol. 34. 1717?1724.
[21]
Xiang Li, Lei Wu, Xu Chen, Lei Meng, and Xiangxu Meng. 2022b. Dse-net: Artistic font image synthesis via disentangled style encoding. In 2022 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 1?6.
[22]
Xiang Li, Lei Wu, Changshuo Wang, Lei Meng, and Xiangxu Meng. 2023. Compositional zero-shot artistic font synthesis. In Proceedings of IJCAI.
[23]
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. 2023. Magic3D: High-Resolution Text-to-3D Content Creation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 300?309.
[24]
Nan Liu, Shuang Li, Yilun Du, Antonio Torralba, and Joshua B Tenenbaum. 2022. Compositional visual generation with composable diffusion models. In European Conference on Computer Vision. Springer, 423?439.
[25]
Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, 2024. Wonder3D: Single Image to 3D using Cross-Domain Diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
[26]
Haokai Ma, Ruobing Xie, Lei Meng, Xin Chen, Xu Zhang, Leyu Lin, and Zhanhui Kang. 2024. Plug-in Diffusion Model for Sequential Recommendation. arXiv preprint arXiv:2401.02913 (2024).
[27]
Gal Metzer, Elad Richardson, Or Patashnik, Raja Giryes, and Daniel Cohen-Or. 2023. Latent-nerf for shape-guided generation of 3d shapes and textures. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12663?12673.
[28]
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. 2020. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In ECCV.
[29]
Nasir Mohammad Khalid, Tianhao Xie, Eugene Belilovsky, and Tiberiu Popa. 2022. Clip-mesh: Generating textured meshes from text using pretrained image-text models. In SIGGRAPH Asia 2022 conference papers. 1?8.
[30]
Thomas M?ller, Alex Evans, Christoph Schied, and Alexander Keller. 2022. Instant Neural Graphics Primitives with a Multiresolution Hash Encoding. ACM Trans. Graph. 41, 4 (2022), 102:1?102:15.
[31]
OpenAI. 2023. Gpt-4 technical report. arXiv preprint arXiv:2209.14988 (2023).
[32]
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. 2023. DreamFusion: Text-to-3D using 2D Diffusion. In The Eleventh International Conference on Learning Representations.
[33]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, 2021. Learning transferable visual models from natural language supervision. In International conference on machine learning. PMLR, 8748?8763.
[34]
Amit Raj, Srinivas Kaza, Ben Poole, Michael Niemeyer, Ben Mildenhall, Nataniel Ruiz, Shiran Zada, Kfir Aberman, Michael Rubenstein, Jonathan Barron, Yuanzhen Li, and Varun Jampani. 2023. DreamBooth3D: Subject-Driven Text-to-3D Generation. ICCV (2023).
[35]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. 2022. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 (2022).
[36]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj?rn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10684?10695.
[37]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, 2022. Photorealistic text-to-image diffusion models with deep language understanding. Advances in Neural Information Processing Systems 35 (2022), 36479?36494.
[38]
Katja Schwarz, Yiyi Liao, Michael Niemeyer, and Andreas Geiger. 2020. Graf: Generative radiance fields for 3d-aware image synthesis. Advances in Neural Information Processing Systems 33 (2020), 20154?20166.
[39]
Tianchang Shen, Jun Gao, Kangxue Yin, Ming-Yu Liu, and Sanja Fidler. 2021. Deep Marching Tetrahedra: a Hybrid Representation for High-Resolution 3D Shape Synthesis. In Advances in Neural Information Processing Systems (NeurIPS).
[40]
Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, and Xiao Yang. 2023. Mvdream: Multi-view diffusion for 3d generation. arXiv preprint arXiv:2308.16512 (2023).
[41]
Jiaming Song, Chenlin Meng, and Stefano Ermon. 2020. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020).
[42]
Weilin Sun, Xiangxian Li, Manyi Li, Yuqing Wang, Yuze Zheng, Xiangxu Meng, and Lei Meng. 2022. Sequential fusion of multi-view video frames for 3D scene generation. In CAAI International Conference on Artificial Intelligence. Springer, 597?608.
[43]
Jiaxiang Tang. 2022. Stable-dreamfusion: Text-to-3D with Stable-diffusion. https://github.com/ashawkey/stable-dreamfusion.
[44]
Yoad Tewel, Rinon Gal, Gal Chechik, and Yuval Atzmon. 2023. Key-locked rank one editing for text-to-image personalization. In ACM SIGGRAPH 2023 Conference Proceedings. 1?11.
[45]
Andrey Voynov, Kfir Aberman, and Daniel Cohen-Or. 2023. Sketch-guided text-to-image diffusion models. In ACM SIGGRAPH 2023 Conference Proceedings. 1?11.
[46]
Can Wang, Menglei Chai, Mingming He, Dongdong Chen, and Jing Liao. 2022. Clip-nerf: Text-and-image driven manipulation of neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3835?3844.
[47]
Changshuo Wang, Lei Wu, Xu Chen, Xiang Li, Lei Meng, and Xiangxu Meng. 2023d. Letter Embedding Guidance Diffusion Model for Scene Text Editing. In 2023 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 588?593.
[48]
Changshuo Wang, Lei Wu, Xiaole Liu, Xiang Li, Lei Meng, and Xiangxu Meng. 2023e. Anything to Glyph: Artistic Font Synthesis via Text-to-Image Diffusion Model. In SIGGRAPH Asia 2023 Conference Papers. 1?11.
[49]
Chi Wang, Min Zhou, Tiezheng Ge, Yuning Jiang, Hujun Bao, and Weiwei Xu. 2023f. CF-Font: Content Fusion for Few-Shot Font Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 1858?1867.
[50]
Haochen Wang, Xiaodan Du, Jiahao Li, Raymond A Yeh, and Greg Shakhnarovich. 2023a. Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12619?12629.
[51]
Yizhi Wang, Yue Gao, and Zhouhui Lian. 2020. Attribute2font: Creating fonts you want from attributes. ACM Transactions on Graphics (TOG) 39, 4 (2020), 69?1.
[52]
Yuqing Wang, Zhuang Qi, Xiangxian Li, Jinxing Liu, Xiangxu Meng, and Lei Meng. 2023c. Multi-channel attentive weighting of visual frames for multimodal video classification. In 2023 International Joint Conference on Neural Networks (IJCNN). IEEE, 1?8.
[53]
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. 2023b. ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation. In Advances in Neural Information Processing Systems (NeurIPS).
[54]
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. 2023a. ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation. arxiv:2304.05977 [cs.CV]
[55]
Jiale Xu, Xintao Wang, Weihao Cheng, Yan-Pei Cao, Ying Shan, Xiaohu Qie, and Shenghua Gao. 2023b. Dream3d: Zero-shot text-to-3d synthesis using 3d shape prior and text-to-image diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 20908?20918.
[56]
Shuai Yang, Jiaying Liu, Wenjing Wang, and Zongming Guo. 2019a. Tet-gan: Text effects transfer via stylization and destylization. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33. 1238?1245.
[57]
Shuai Yang, Zhangyang Wang, and Jiaying Liu. 2022. Shape-Matching GAN++: Scale Controllable Dynamic Artistic Text Style Transfer. IEEE Transactions on Pattern Analysis and Machine Intelligence 44, 7 (2022), 3807?3820. https://doi.org/10.1109/TPAMI.2021.3055211
[58]
Shuai Yang, Zhangyang Wang, Zhaowen Wang, Ning Xu, Jiaying Liu, and Zongming Guo. 2019b. Controllable artistic text style transfer via shape-matching gan. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 4442?4451.
[59]
Guo Yuanchen, Liu Yingtian, and Shao et al. Ruizhi. 2023. Threestudio: A unified framework for 3d content generation. https://github.com/threestudio-project/threestudio.
[60]
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. 2023. Adding Conditional Control to Text-to-Image Diffusion Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV).