
“DiffCAD: Weakly-supervised Probabilistic CAD Model Retrieval and Alignment From an RGB Image”
Conference:
Type(s):
Title:
- DiffCAD: Weakly-supervised Probabilistic CAD Model Retrieval and Alignment From an RGB Image
Presenter(s)/Author(s):
Abstract:
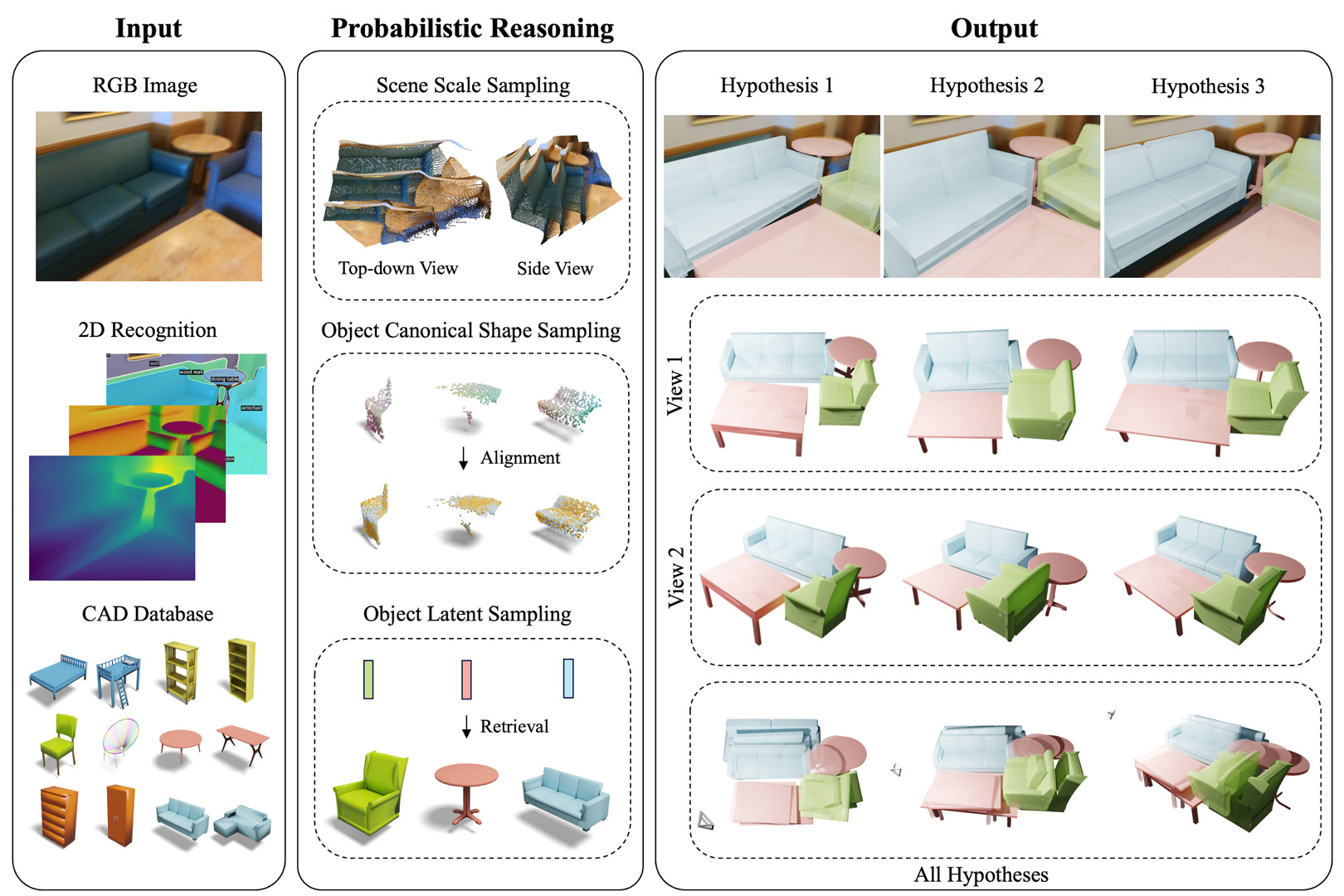
DiffCAD introduces probabilistic CAD retrieval and alignment to an RGB image. It models the disentangled distributions of scene scale, object pose, and shape leveraging diffusion. This enables cross-domain multi hypothesis CAD reconstruction, capturing the inherent ambiguities in depth/scale and object shape/pose, while only trained on synthetic data.
References:
[1]
Armen Avetisyan, Manuel Dahnert, Angela Dai, Manolis Savva, Angel X Chang, and Matthias Nie?ner. 2019a. Scan2cad: Learning cad model alignment in rgb-d scans. In Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition. 2614–2623.
[2]
Armen Avetisyan, Angela Dai, and Matthias Nie?ner. 2019b. End-to-end cad model retrieval and 9dof alignment in 3d scans. In Proceedings of the IEEE/CVF International Conference on computer vision. 2551–2560.
[3]
Armen Avetisyan, Tatiana Khanova, Christopher Choy, Denver Dash, Angela Dai, and Matthias Nie?ner. 2020. Scenecad: Predicting object alignments and layouts in rgb-d scans. In Computer Vision-ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXII 16. Springer, 596–612.
[4]
Gwangbin Bae, Ignas Budvytis, and Roberto Cipolla. 2022. IronDepth: Iterative Refinement of Single-View Depth using Surface Normal and its Uncertainty. ArXiv abs/2210.03676 (2022). https://api.semanticscholar.org/CorpusID:252762221
[5]
Dmitry Baranchuk, Ivan Rubachev, Andrey Voynov, Valentin Khrulkov, and Artem Babenko. 2021. Label-Efficient Semantic Segmentation with Diffusion Models. ArXiv abs/2112.03126 (2021). https://api.semanticscholar.org/CorpusID:244908617
[6]
Gilad Baruch, Zhuoyuan Chen, Afshin Dehghan, Tal Dimry, Yuri Feigin, Peter Fu, Thomas Gebauer, Brandon Joffe, Daniel Kurz, Arik Schwartz, and Elad Shulman. 2021. ARKitScenes – A Diverse Real-World Dataset for 3D Indoor Scene Understanding Using Mobile RGB-D Data. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1). https://openreview.net/forum?id=tjZjv_qh_CE
[7]
Tim Beyer and Angela Dai. 2022. Weakly-Supervised End-to-End CAD Retrieval to Scan Objects. ArXiv abs/2203.12873 (2022). https://api.semanticscholar.org/CorpusID:247627889
[8]
S. Bhat, Ibraheem Alhashim, and Peter Wonka. 2020. AdaBins: Depth Estimation Using Adaptive Bins. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2020), 4008–4017. https://api.semanticscholar.org/CorpusID:227227779
[9]
Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter Wonka, and Matthias M?ller. 2023. Zoedepth: Zero-shot transfer by combining relative and metric depth. arXiv preprint arXiv:2302.12288 (2023).
[10]
Andreas Blattmann, Robin Rombach, Kaan Oktay, Jonas M?ller, and Bj?rn Ommer. 2022. Retrieval-augmented diffusion models. Advances in Neural Information Processing Systems 35 (2022), 15309–15324.
[11]
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. 2020. End-to-End Object Detection with Transformers. ArXiv abs/2005.12872 (2020). https://api.semanticscholar.org/CorpusID:218889832
[12]
Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. 2015. Shapenet: An information-rich 3d model repository. arXiv preprint arXiv:1512.03012 (2015).
[13]
Wenhu Chen, Hexiang Hu, Chitwan Saharia, and William W. Cohen. 2022. Re-Imagen: Retrieval-Augmented Text-to-Image Generator. ArXiv abs/2209.14491 (2022). https://api.semanticscholar.org/CorpusID:252596087
[14]
Yen-Chi Cheng, Hsin-Ying Lee, Sergey Tulyakov, Alexander G Schwing, and Liang-Yan Gui. 2023. Sdfusion: Multimodal 3d shape completion, reconstruction, and generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4456–4465.
[15]
Gene Chou, Yuval Bahat, and Felix Heide. 2022. DiffusionSDF: Conditional Generative Modeling of Signed Distance Functions. ArXiv abs/2211.13757 (2022). https://api.semanticscholar.org/CorpusID:254017862
[16]
Gene Chou, Yuval Bahat, and Felix Heide. 2023. Diffusion-sdf: Conditional generative modeling of signed distance functions. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 2262–2272.
[17]
Christopher B Choy, Danfei Xu, JunYoung Gwak, Kevin Chen, and Silvio Savarese. 2016. 3d-r2n2: A unified approach for single and multi-view 3d object reconstruction. In Computer Vision-ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part VIII 14. Springer, 628–644.
[18]
Sanghyuk Chun, Seong Joon Oh, Rafael Sampaio De Rezende, Yannis Kalantidis, and Diane Larlus. 2021. Probabilistic embeddings for cross-modal retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8415–8424.
[19]
Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nie?ner. 2017. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition. 5828–5839.
[20]
Congyue Deng, Chiyu Max Jiang, C. Qi, Xinchen Yan, Yin Zhou, Leonidas J. Guibas, and Drago Anguelov. 2022. NeRDi: Single-View NeRF Synthesis with Language-Guided Diffusion as General Image Priors. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022), 20637–20647. https://api.semanticscholar.org/CorpusID:254366717
[21]
Maximilian Denninger, Dominik Winkelbauer, Martin Sundermeyer, Wout Boerdijk, Markus Knauer, Klaus H. Strobl, Matthias Humt, and Rudolph Triebel. 2023. Blender-Proc2: A Procedural Pipeline for Photorealistic Rendering. Journal of Open Source Software 8, 82 (2023), 4901.
[22]
Yan Di, Chenyangguang Zhang, Ruida Zhang, Fabian Manhardt, Yongzhi Su, Jason Rambach, Didier Stricker, Xiangyang Ji, and Federico Tombari. 2023. U-RED: Unsupervised 3D Shape Retrieval and Deformation for Partial Point Clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 8884–8895.
[23]
Christian Diller and Angela Dai. 2023. CG-HOI: Contact-Guided 3D Human-Object Interaction Generation. arXiv preprint arXiv:2311.16097 (2023).
[24]
Ainaz Eftekhar, Alexander Sax, Jitendra Malik, and Amir Zamir. 2021. Omnidata: A Scalable Pipeline for Making Multi-Task Mid-Level Vision Datasets From 3D Scans. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 10786–10796.
[25]
Ziya Erko?, Fangchang Ma, Qi Shan, Matthias Nie?ner, and Angela Dai. 2023. Hyperdiffusion: Generating implicit neural fields with weight-space diffusion. arXiv preprint arXiv:2303.17015 (2023).
[26]
Haoqiang Fan, Hao Su, and Leonidas J Guibas. 2017. A point set generation network for 3d object reconstruction from a single image. In Proceedings of the IEEE conference on computer vision and pattern recognition. 605–613.
[27]
Yuxin Fang, Wen Wang, Binhui Xie, Quan-Sen Sun, Ledell Yu Wu, Xinggang Wang, Tiejun Huang, Xinlong Wang, and Yue Cao. 2022. EVA: Exploring the Limits of Masked Visual Representation Learning at Scale. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022), 19358–19369. https://api.semanticscholar.org/CorpusID:253510587
[28]
Martin A Fischler and Robert C Bolles. 1981. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 24, 6 (1981), 381–395.
[29]
Huan Fu, Bowen Cai, Lin Gao, Ling-Xiao Zhang, Jiaming Wang, Cao Li, Qixun Zeng, Chengyue Sun, Rongfei Jia, Binqiang Zhao, et al. 2021. 3d-front: 3d furnished rooms with layouts and semantics. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 10933–10942.
[30]
Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, and Jian Sun. 2021. Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430 (2021).
[31]
Golnaz Ghiasi, Xiuye Gu, Yin Cui, and Tsung-Yi Lin. 2022. Scaling Open-Vocabulary Image Segmentation with Image-Level Labels. In ECCV.
[32]
Georgia Gkioxari, Jitendra Malik, and Justin Johnson. 2019. Mesh r-cnn. In Proceedings of the IEEE/CVF international conference on computer vision. 9785–9795.
[33]
Vitor Guizilini, Igor Vasiljevic, Dian Chen, Rares Ambrus, and Adrien Gaidon. 2023. Towards Zero-Shot Scale-Aware Monocular Depth Estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV).
[34]
Can G?meli, Angela Dai, and Matthias Nie?ner. 2022. Roca: Robust cad model retrieval and alignment from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4022–4031.
[35]
Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. 2022. Generating diverse and natural 3d human motions from text. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5152–5161.
[36]
Kaiming He, Georgia Gkioxari, Piotr Doll?r, and Ross Girshick. 2017. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision. 2961–2969.
[37]
Eric Hedlin, Gopal Sharma, Shweta Mahajan, Hossam Isack, Abhishek Kar, Andrea Tagliasacchi, and Kwang Moo Yi. 2023. Unsupervised Semantic Correspondence Using Stable Diffusion. arXiv preprint arXiv:2305.15581 (2023).
[38]
Jonathan Ho, Ajay Jain, and P. Abbeel. 2020. Denoising Diffusion Probabilistic Models. ArXiv abs/2006.11239 (2020). https://api.semanticscholar.org/CorpusID:219955663
[39]
Muhammad Zubair Irshad, Thomas Kollar, Michael Laskey, Kevin Stone, and Zsolt Kira. 2022. CenterSnap: Single-Shot Multi-Object 3D Shape Reconstruction and Categorical 6D Pose and Size Estimation. 2022 International Conference on Robotics and Automation (ICRA) (2022), 10632–10640. https://api.semanticscholar.org/CorpusID:247222831
[40]
Vladislav Ishimtsev, Alexey Bokhovkin, Alexey Artemov, Savva Ignatyev, Matthias Niessner, Denis Zorin, and Evgeny Burnaev. 2020. Cad-deform: Deformable fitting of cad models to 3d scans. In Computer Vision-ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIII 16. Springer, 599–628.
[41]
Hamid Izadinia, Qi Shan, and Steven M Seitz. 2017. Im2cad. In Proceedings of the IEEE conference on computer vision and pattern recognition. 5134–5143.
[42]
Young Min Kim, Niloy J Mitra, Dong-Ming Yan, and Leonidas Guibas. 2012. Acquiring 3d indoor environments with variability and repetition. ACM Transactions on Graphics (TOG) 31, 6 (2012), 1–11.
[43]
Diederik P. Kingma, Tim Salimans, Ben Poole, and Jonathan Ho. 2021. Variational Diffusion Models. ArXiv abs/2107.00630 (2021). https://api.semanticscholar.org/CorpusID:235694314
[44]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. 2023. Segment anything. arXiv preprint arXiv:2304.02643 (2023).
[45]
Juil Koo, Seungwoo Yoo, Minh Hoai Nguyen, and Minhyuk Sung. 2023. SALAD: Part-Level Latent Diffusion for 3D Shape Generation and Manipulation. ArXiv abs/2303.12236 (2023). https://api.semanticscholar.org/CorpusID:257663544
[46]
Weicheng Kuo, Anelia Angelova, Tsung-Yi Lin, and Angela Dai. 2020. Mask2cad: 3d shape prediction by learning to segment and retrieve. In Computer Vision-ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16. Springer, 260–277.
[47]
Weicheng Kuo, Anelia Angelova, Tsung-Yi Lin, and Angela Dai. 2021. Patch2cad: Patchwise embedding learning for in-the-wild shape retrieval from a single image. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 12589–12599.
[48]
Florian Langer, Gwangbin Bae, Ignas Budvytis, and Roberto Cipolla. 2022. SPARC: Sparse Render-and-Compare for CAD model alignment in a single RGB image. arXiv preprint arXiv:2210.01044 (2022).
[49]
Florian Langer, Ignas Budvytis, and Roberto Cipolla. 2023. Sparse Multi-Object Render-and-Compare. arXiv preprint arXiv:2310.11184 (2023).
[50]
Boyi Li, Kilian Q. Weinberger, Serge J. Belongie, Vladlen Koltun, and Ren? Ranftl. 2022c. Language-driven Semantic Segmentation. ArXiv abs/2201.03546 (2022). https://api.semanticscholar.org/CorpusID:245836975
[51]
Muheng Li, Yueqi Duan, Jie Zhou, and Jiwen Lu. 2022b. Diffusion-SDF: Text-to-Shape via Voxelized Diffusion. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022), 12642–12651. https://api.semanticscholar.org/CorpusID:254366593
[52]
Yangyan Li, Angela Dai, Leonidas Guibas, and Matthias Nie?ner. 2015. Database-assisted object retrieval for real-time 3d reconstruction. In Computer graphics forum, Vol. 34. Wiley Online Library, 435–446.
[53]
Zhenyu Li, Zehui Chen, Xianming Liu, and Junjun Jiang. 2022a. DepthFormer: Exploiting Long-range Correlation and Local Information for Accurate Monocular Depth Estimation. Machine Intelligence Research 20 (2022), 837 — 854. https://api.semanticscholar.org/CorpusID:247762153
[54]
Feng Liang, Bichen Wu, Xiaoliang Dai, Kunpeng Li, Yinan Zhao, Hang Zhang, Peizhao Zhang, P?ter Vajda, and Diana Marculescu. 2022. Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022), 7061–7070. https://api.semanticscholar.org/CorpusID:252780581
[55]
Kai-En Lin, Yen-Chen Lin, Wei-Sheng Lai, Tsung-Yi Lin, Yichang Shih, and Ravi Ramamoorthi. 2022. Vision Transformer for NeRF-Based View Synthesis from a Single Input Image. 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) (2022), 806–815. https://api.semanticscholar.org/CorpusID:250450901
[56]
Tsung-Yi Lin, Piotr Doll?r, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. 2017. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition. 2117–2125.
[57]
Zhi-Hao Lin, Sheng-Yu Huang, and Yu-Chiang Frank Wang. 2020. Convolution in the cloud: Learning deformable kernels in 3d graph convolution networks for point cloud analysis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 1800–1809.
[58]
Haolin Liu, Yujian Zheng, Guanying Chen, Shuguang Cui, and Xiaoguang Han. 2022. Towards High-Fidelity Single-view Holistic Reconstruction of Indoor Scenes. ArXiv abs/2207.08656 (2022). https://api.semanticscholar.org/CorpusID:250627520
[59]
Jonathan Long, Evan Shelhamer, and Trevor Darrell. 2015. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition. 3431–3440.
[60]
Grace Luo, Lisa Dunlap, Dong Huk Park, Aleksander Holynski, and Trevor Darrell. 2023. Diffusion Hyperfeatures: Searching Through Time and Space for Semantic Correspondence. In Advances in Neural Information Processing Systems.
[61]
Priyanka Mandikal, L. NavaneetK., Mayank Agarwal, and R. Venkatesh Babu. 2018. 3D-LMNet: Latent Embedding Matching for Accurate and Diverse 3D Point Cloud Reconstruction from a Single Image. ArXiv abs/1807.07796 (2018). https://api.semanticscholar.org/CorpusID:49905039
[62]
Kevis-Kokitsi Maninis, Stefan Popov, Matthias Nie?ner, and Vittorio Ferrari. 2022. Vid2cad: Cad model alignment using multi-view constraints from videos. IEEE transactions on pattern analysis and machine intelligence 45, 1 (2022), 1320–1327.
[63]
Lars Mescheder, Michael Oechsle, Michael Niemeyer, Sebastian Nowozin, and Andreas Geiger. 2019. Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 4460–4470.
[64]
Gimin Nam, Mariem Khlifi, Andrew Rodriguez, Alberto Tono, Linqi Zhou, and Paul Guerrero. 2022. 3D-LDM: Neural Implicit 3D Shape Generation with Latent Diffusion Models. ArXiv abs/2212.00842 (2022). https://api.semanticscholar.org/CorpusID:254220714
[65]
Liangliang Nan, Ke Xie, and Andrei Sharf. 2012. A search-classify approach for cluttered indoor scene understanding. ACM Transactions on Graphics (TOG) 31, 6 (2012), 1–10.
[66]
Andrei Neculai, Yanbei Chen, and Zeynep Akata. 2022. Probabilistic compositional embeddings for multimodal image retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4547–4557.
[67]
Yinyu Nie, Xiaoguang Han, Shihui Guo, Yujian Zheng, Jian Chang, and Jianjun Zhang. 2020. Total3DUnderstanding: Joint Layout, Object Pose and Mesh Reconstruction for Indoor Scenes From a Single Image. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2020), 52–61. https://api.semanticscholar.org/CorpusID:211532831
[68]
Junyi Pan, Xiaoguang Han, Weikai Chen, Jiapeng Tang, and Kui Jia. 2019. Deep Mesh Reconstruction From Single RGB Images via Topology Modification Networks. 2019 IEEE/CVF International Conference on Computer Vision (ICCV) (2019), 9963–9972. https://api.semanticscholar.org/CorpusID:202121070
[69]
William Peebles and Saining Xie. 2023. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 4195–4205.
[70]
Songyou Peng, Michael Niemeyer, Lars Mescheder, Marc Pollefeys, and Andreas Geiger. 2020. Convolutional occupancy networks. In Computer Vision-ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16. Springer, 523–540.
[71]
Michael Ramamonjisoa and Vincent Lepetit. 2019. SharpNet: Fast and Accurate Recovery of Occluding Contours in Monocular Depth Estimation. 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW) (2019), 2109–2118. https://api.semanticscholar.org/CorpusID:160009795
[72]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. 2022. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 1, 2 (2022), 3.
[73]
Ren? Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. 2021. Vision transformers for dense prediction. In Proceedings of the IEEE/CVF international conference on computer vision. 12179–12188.
[74]
Nikhila Ravi, Jeremy Reizenstein, David Novotny, Taylor Gordon, Wan-Yen Lo, Justin Johnson, and Georgia Gkioxari. 2020. Accelerating 3d deep learning with pytorch3d. arXiv preprint arXiv:2007.08501 (2020).
[75]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj?rn Ommer. 2021. High-Resolution Image Synthesis with Latent Diffusion Models. arXiv:2112.10752 [cs.CV]
[76]
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. 2015. Imagenet large scale visual recognition challenge. International journal of computer vision 115 (2015), 211–252.
[77]
Manuel Schwonberg, Joshua Niemeijer, Jan-Aike Term?hlen, J?rg P Sch?fer, Nico M Schmidt, Hanno Gottschalk, and Tim Fingscheidt. 2023. Survey on unsupervised domain adaptation for semantic segmentation for visual perception in automated driving. IEEE Access (2023).
[78]
Tianjia Shao, Weiwei Xu, Kun Zhou, Jingdong Wang, Dongping Li, and Baining Guo. 2012. An interactive approach to semantic modeling of indoor scenes with an rgbd camera. ACM Transactions on Graphics (TOG) 31, 6 (2012), 1–11.
[79]
Shelly Sheynin, Oron Ashual, Adam Polyak, Uriel Singer, Oran Gafni, Eliya Nachmani, and Yaniv Taigman. 2022. Knn-diffusion: Image generation via large-scale retrieval. arXiv preprint arXiv:2204.02849 (2022).
[80]
J Ryan Shue, Eric Ryan Chan, Ryan Po, Zachary Ankner, Jiajun Wu, and Gordon Wetzstein. 2023. 3d neural field generation using triplane diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 20875–20886.
[81]
Jascha Narain Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli. 2015. Deep Unsupervised Learning using Nonequilibrium Thermodynamics. ArXiv abs/1503.03585 (2015). https://api.semanticscholar.org/CorpusID:14888175
[82]
Yang Song and Stefano Ermon. 2019. Generative modeling by estimating gradients of the data distribution. Advances in neural information processing systems 32 (2019).
[83]
Yang Song, Jascha Narain Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. 2020. Score-Based Generative Modeling through Stochastic Differential Equations. ArXiv abs/2011.13456 (2020). https://api.semanticscholar.org/CorpusID:227209335
[84]
David Stutz and Andreas Geiger. 2020. Learning 3d shape completion under weak supervision. International Journal of Computer Vision 128 (2020), 1162–1181.
[85]
Luming Tang, Menglin Jia, Qianqian Wang, Cheng Perng Phoo, and Bharath Hariharan. 2023. Emergent Correspondence from Image Diffusion. arXiv preprint arXiv:2306.03881 (2023).
[86]
Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, and Amit H Bermano. 2022. Human motion diffusion model. arXiv preprint arXiv:2209.14916 (2022).
[87]
Mikaela Angelina Uy, Jingwei Huang, Minhyuk Sung, Tolga Birdal, and Leonidas Guibas. 2020. Deformation-aware 3d model embedding and retrieval. In Computer Vision-ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VII 16. Springer, 397–413.
[88]
Mikaela Angelina Uy, Vladimir G Kim, Minhyuk Sung, Noam Aigerman, Siddhartha Chaudhuri, and Leonidas J Guibas. 2021. Joint learning of 3d shape retrieval and deformation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11713–11722.
[89]
Qun Wan, Yidong Li, Haidong Cui, and Zheng Mao Feng. 2019. 3D-Mask-GAN:Unsupervised Single-View 3D Object Reconstruction. 2019 6th International Conference on Behavioral, Economic and Socio-Cultural Computing (BESC) (2019), 1–6. https://api.semanticscholar.org/CorpusID:210888106
[90]
He Wang, Srinath Sridhar, Jingwei Huang, Julien Valentin, Shuran Song, and Leonidas J Guibas. 2019. Normalized object coordinate space for category-level 6d object pose and size estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2642–2651.
[91]
Nanyang Wang, Yinda Zhang, Zhuwen Li, Yanwei Fu, W. Liu, and Yu-Gang Jiang. 2018. Pixel2Mesh: Generating 3D Mesh Models from Single RGB Images. ArXiv abs/1804.01654 (2018). https://api.semanticscholar.org/CorpusID:4633214
[92]
Bowen Wen, Wenzhao Lian, Kostas Bekris, and Stefan Schaal. 2022. CaTGrasp: Learning Category-Level Task-Relevant Grasping in Clutter from Simulation. ICRA 2022 (2022).
[93]
Xiaoyang Wu, Li Jiang, Peng-Shuai Wang, Zhijian Liu, Xihui Liu, Yu Qiao, Wanli Ouyang, Tong He, and Hengshuang Zhao. 2023. Point transformer v3: Simpler, faster, stronger. arXiv preprint arXiv:2312.10035 (2023).
[94]
Jiarui Xu, Sifei Liu, Arash Vahdat, Wonmin Byeon, Xiaolong Wang, and Shalini De Mello. 2023. Open-vocabulary panoptic segmentation with text-to-image diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2955–2966.
[95]
Alex Yu, Vickie Ye, Matthew Tancik, and Angjoo Kanazawa. 2020. pixelNeRF: Neural Radiance Fields from One or Few Images. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2020), 4576–4585. https://api.semanticscholar.org/CorpusID:227254854
[96]
Yanjie Ze and Xiaolong Wang. 2022. Category-level 6d object pose estimation in the wild: A semi-supervised learning approach and a new dataset. Advances in Neural Information Processing Systems 35 (2022), 27469–27483.
[97]
Xiaohui Zeng, Arash Vahdat, Francis Williams, Zan Gojcic, Or Litany, Sanja Fidler, and Karsten Kreis. 2022. LION: Latent Point Diffusion Models for 3D Shape Generation. ArXiv abs/2210.06978 (2022). https://api.semanticscholar.org/CorpusID:252872881
[98]
Biao Zhang, Jiapeng Tang, Matthias Nie?ner, and Peter Wonka. 2023. 3DShape2VecSet: A 3D Shape Representation for Neural Fields and Generative Diffusion Models. ACM Transactions on Graphics (TOG) 42 (2023), 1 — 16. https://api.semanticscholar.org/CorpusID:256358401
[99]
Cheng Zhang, Zhaopeng Cui, Yinda Zhang, Bing Zeng, Marc Pollefeys, and Shuaicheng Liu. 2021. Holistic 3D Scene Understanding from a Single Image with Implicit Representation. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2021), 8829–8838. https://api.semanticscholar.org/CorpusID:232185507
[100]
Jiyao Zhang, Mingdong Wu, and Hao Dong. 2024. Generative Category-level Object Pose Estimation via Diffusion Models. Advances in Neural Information Processing Systems 36 (2024).
[101]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. 2018. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition. 586–595.
[102]
Linqi Zhou, Yilun Du, and Jiajun Wu. 2021. 3D Shape Generation and Completion through Point-Voxel Diffusion. 2021 IEEE/CVF International Conference on Computer Vision (ICCV) (2021), 5806–5815. https://api.semanticscholar.org/CorpusID:233182041