
“CLIPXPlore: Coupled CLIP and Shape Spaces for 3D Shape Exploration” by Hu, Hui, Liu, Zhang and Fu
Conference:
Type(s):
Title:
- CLIPXPlore: Coupled CLIP and Shape Spaces for 3D Shape Exploration
Session/Category Title:
- Navigating Shape Spaces
Presenter(s)/Author(s):
Abstract:
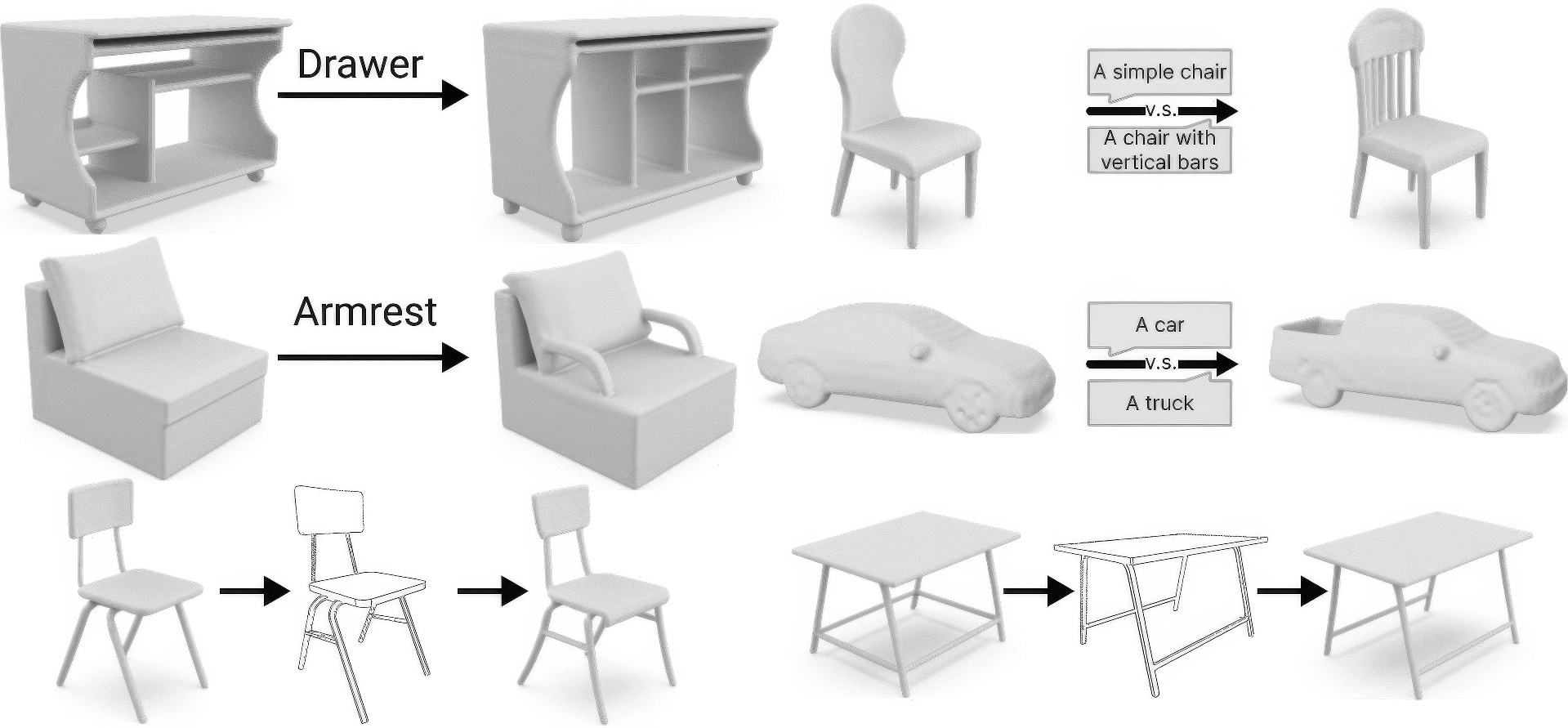
This paper presents CLIPXPlore, a new framework that leverages a vision-language model to guide the exploration of the 3D shape space. Many recent methods have been developed to encode 3D shapes into a learned latent shape space to enable generative design and modeling. Yet, existing methods lack effective exploration mechanisms, despite the rich information. To this end, we propose to leverage CLIP, a powerful pre-trained vision-language model, to aid the shape space exploration. Our idea is threefold. First, we couple the CLIP and shape spaces by generating paired CLIP and shape codes through sketch images and training a mapper network to connect the two spaces. Second, to explore the space around a given shape, we formulate a co-optimization strategy to search for the CLIP code that better matches the geometry of the shape. Third, we design three exploration scenarios, binary-attribute-guided, text-guided, and sketch-guided, to locate suitable exploration trajectories in shape space and induce meaningful changes to the shape. We perform a series of experiments to quantitatively and visually compare CLIPXPlore with different baselines in each of the three scenarios, showing that CLIPXPlore can produce many meaningful exploration results that cannot be achieved by the existing solutions.
References:
[1]
2009. Exploratory modeling with collaborative design spaces. 28, 5 (2009), 1–10.
[2]
Rameen Abdal, Yipeng Qin, and Peter Wonka. 2019. Image2stylegan: How to embed images into the stylegan latent space?. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 4432–4441.
[3]
Rameen Abdal, Peihao Zhu, John Femiani, Niloy Mitra, and Peter Wonka. 2022. Clip2stylegan: Unsupervised extraction of stylegan edit directions. In Proceedings of SIGGRAPH. 1–9.
[4]
Rameen Abdal, Peihao Zhu, Niloy J Mitra, and Peter Wonka. 2021. Styleflow: Attribute-conditioned exploration of stylegan-generated images using conditional continuous normalizing flows. In ACM Transactions on Graphics (SIGGRAPH), Vol. 40. 1–21.
[5]
Panos Achlioptas, Olga Diamanti, Ioannis Mitliagkas, and Leonidas J. Guibas. 2018. Learning representations and generative models for 3D point clouds. In Proceedings of International Conference on Machine Learning (ICML). 40–49.
[6]
Panos Achlioptas, Ian Huang, Minhyuk Sung, Sergey Tulyakov, and Leonidas Guibas. 2023. ChangeIt3D: Language-Assisted 3D Shape Edits and Deformations. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[7]
Melinos Averkiou, Vladimir G. Kim, Youyi Zheng, and Niloy J. Mitra. 2014. ShapeSynth: Parameterizing model collections for coupled shape exploration and synthesis. Computer Graphics Forum 33, 2 (2014), 125–134.
[8]
Kunal Gupta Manmohan Chandraker. 2020. Neural Mesh Flow: 3D Manifold Mesh Generation via Diffeomorphic Flows. In Conference on Neural Information Processing Systems (NeurIPS). 1747–1758.
[9]
Angel X. Chang, Thomas Funkhouser, Leonidas J. Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, 2015. ShapeNet: An information-rich 3D model repository. arXiv preprint arXiv:1512.03012 (2015).
[10]
Siddhartha Chaudhuri and Vladlen Koltun. 2010. Data-driven suggestions for creativity support in 3D modeling. ACM Transactions on Graphics 29, 6 (2010), Article 183.
[11]
Kevin Chen, Christopher B Choy, Manolis Savva, Angel X Chang, Thomas Funkhouser, and Silvio Savarese. 2019. Text2shape: Generating shapes from natural language by learning joint embeddings. In Asia Conference on Computer Vision (ACCV). 100–116.
[12]
Zhiqin Chen, Andrea Tagliasacchi, and Hao Zhang. 2020. BSP-Net: Generating compact meshes via binary space partitioning. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 45–54.
[13]
Zhiqin Chen and Hao Zhang. 2019. Learning implicit fields for generative shape modeling. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 5939–5948.
[14]
Yen-Chi Cheng, Hsin-Ying Lee, Sergey Tulyakov, Alexander Schwing, and Liangyan Gui. 2023. SDFusion: Multimodal 3D Shape Completion, Reconstruction, and Generation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[15]
Zezhou Cheng, Menglei Chai, Jian Ren, Hsin-Ying Lee, Kyle Olszewski, Zeng Huang, Subhransu Maji, and Sergey Tulyakov. 2022. Cross-modal 3d shape generation and manipulation. In European Conference on Computer Vision (ECCV). 303–321.
[16]
Anton Cherepkov, Andrey Voynov, and Artem Babenko. 2021. Navigating the gan parameter space for semantic image editing. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 3671–3680.
[17]
Chia-Hsing Chiu, Yuki Koyama, Yu-Chi Lai, Takeo Igarashi, and Yonghao Yue. 2020. Human-in-the-Loop Differential Subspace Search in High-Dimensional Latent Space. In ACM Transactions on Graphics (SIGGRAPH), Vol. 39. 85–1.
[18]
Bob Coyne and Richard Sproat. 2001. WordsEye: An Automatic Text-to-scene Conversion System. In Proceedings of SIGGRAPH. 487–496.
[19]
Johanna Delanoy, Mathieu Aubry, Phillip Isola, Alexei A Efros, and Adrien Bousseau. 2018. 3d sketching using multi-view deep volumetric prediction. Proceedings of the ACM on Computer Graphics and Interactive Techniques 1, 1 (2018), 1–22.
[20]
Chao Ding and Ligang Liu. 2016. A survey of sketch based modeling systems. Frontiers of Computer Science 10, 6 (2016), 985–999.
[21]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, 2020. An image is worth 16×16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020).
[22]
Rao Fu, Xiao Zhan, Yiwen Chen, Daniel Ritchie, and Srinath Sridhar. 2022. Shapecrafter: A recursive text-conditioned 3d shape generation model. Conference on Neural Information Processing Systems (NeurIPS).
[23]
Rinon Gal, Amit Bermano, Hao Zhang, and Daniel Cohen-Or. 2020. MRGAN: Multi-Rooted 3D Shape Generation with Unsupervised Part Disentanglement. In IEEE International Conference on Computer Vision (ICCV). 2039–2048.
[24]
Rinon Gal, Or Patashnik, Haggai Maron, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. 2022. StyleGAN-NADA: CLIP-guided domain adaptation of image generators. In ACM Transactions on Graphics (SIGGRAPH), Vol. 41. 1–13.
[25]
Chenjian Gao, Qian Yu, Lu Sheng, Yi-Zhe Song, and Dong Xu. 2022b. SketchSampler: Sketch-Based 3D Reconstruction via View-Dependent Depth Sampling. In European Conference on Computer Vision (ECCV). 464–479.
[26]
Jun Gao, Tianchang Shen, Zian Wang, Wenzheng Chen, Kangxue Yin, Daiqing Li, Or Litany, Zan Gojcic, and Sanja Fidler. 2022a. GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images. In Conference on Neural Information Processing Systems (NeurIPS).
[27]
William Gao, Noam Aigerman, Groueix Thibault, Vladimir Kim, and Rana Hanocka. 2023. TextDeformer: Geometry Manipulation using Text Guidance. In ACM Transactions on Graphics (SIGGRAPH).
[28]
Lore Goetschalckx, Alex Andonian, Aude Oliva, and Phillip Isola. 2019. Ganalyze: Toward visual definitions of cognitive image properties. In IEEE International Conference on Computer Vision (ICCV). 5744–5753.
[29]
Thibault Groueix, Matthew Fisher, Vladimir G. Kim, Bryan Russell, and Mathieu Aubry. 2018. AtlasNet: A Papier-Mâché Approach to Learning 3D Surface Generation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 216–224.
[30]
Benoit Guillard, Edoardo Remelli, Pierre Yvernay, and Pascal Fua. 2021. Sketch2mesh: Reconstructing and editing 3d shapes from sketches. In IEEE International Conference on Computer Vision (ICCV). 13023–13032.
[31]
Zhizhong Han, Baorui Ma, Yu-Shen Liu, and Matthias Zwicker. 2020. Reconstructing 3D shapes from multiple sketches using direct shape optimization. IEEE Transactions Image Processing 29 (2020), 8721–8734.
[32]
Erik Härkönen, Aaron Hertzmann, Jaakko Lehtinen, and Sylvain Paris. 2020. Ganspace: Discovering interpretable gan controls. In Conference on Neural Information Processing Systems (NeurIPS). 9841–9850.
[33]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 770–778.
[34]
Amir Hertz, Or Perel, Raja Giryes, Olga Sorkine-Hornung, and Daniel Cohen-Or. 2022. SPAGHETTI: Editing Implicit Shapes Through Part Aware Generation. arXiv preprint arXiv:2201.13168 (2022).
[35]
Fangzhou Hong, Mingyuan Zhang, Liang Pan, Zhongang Cai, Lei Yang, and Ziwei Liu. 2022. AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars. ACM Transactions on Graphics (TOG) 41, 4 (2022), 1–19.
[36]
Ian Huang, Panos Achlioptas, Tianyi Zhang, Sergey Tulyakov, Minhyuk Sung, and Leonidas Guibas. 2022. LADIS: Language disentanglement for 3D shape editing. In In Findings of Empirical Methods in Natural Language Processing (EMNLP).
[37]
Ka-Hei Hui, Ruihui Li, Jingyu Hu, and Chi-Wing Fu. 2022. Neural wavelet-domain diffusion for 3d shape generation. In Proceedings of SIGGRAPH Asia. 1–9.
[38]
Le Hui, Rui Xu, Jin Xie, Jianjun Qian, and Jian Yang. 2020. Progressive point cloud deconvolution generation network. In European Conference on Computer Vision (ECCV). 397–413.
[39]
Takeo Igarashi, Satoshi Matsuoka, and Hidehiko Tanaka. 1999. Teddy: a sketching interface for 3D freeform design. In Proceedings of SIGGRAPH. 409–416.
[40]
Tansin Jahan, Yanran Guan, and Oliver Van Kaick. 2021. Semantics-Guided Latent Space Exploration for Shape Generation. In Computer Graphics Forum, Vol. 40. 115–126.
[41]
Ajay Jain, Ben Mildenhall, Jonathan T Barron, Pieter Abbeel, and Ben Poole. 2022. Zero-shot text-guided object generation with dream fields. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 867–876.
[42]
Tero Karras, Miika Aittala, Samuli Laine, Erik Härkönen, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2021. Alias-free generative adversarial networks. In Conference on Neural Information Processing Systems (NeurIPS). 852–863.
[43]
Tero Karras, Samuli Laine, and Timo Aila. 2019. A style-based generator architecture for generative adversarial networks. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 4401–4410.
[44]
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2020. Analyzing and improving the image quality of stylegan. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 8110–8119.
[45]
Nasir Khalid, Tianhao Xie, Eugene Belilovsky, and Tiberiu Popa. 2022. CLIP-Mesh: Generating textured meshes from text using pretrained image-text models. In Proceedings of SIGGRAPH Asia. 1–8.
[46]
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
[47]
Changjian Li, Hao Pan, Yang Liu, Xin Tong, Alla Sheffer, and Wenping Wang. 2018. Robust flow-guided neural prediction for sketch-based freeform surface modeling. ACM Transactions on Graphics (SIGGRAPH Asia) 37, 6, 1–12.
[48]
Yuhan Li, Yishun Dou, Xuanhong Chen, Bingbing Ni, Yilin Sun, Yutian Liu, and Fuzhen Wang. 2023. 3DQD: Generalized Deep 3D Shape Prior via Part-Discretized Diffusion Process. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[49]
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. 2023. Magic3d: High-resolution text-to-3d content creation. In Conference on Neural Information Processing Systems (NeurIPS). 300–309.
[50]
Zhengzhe Liu, Peng Dai, Ruihui Li, Xiaojuan Qi, and Chi-Wing Fu. 2022a. Iss: Image as stetting stone for text-guided 3d shape generation. In International Conference on Learning Representations (ICLR).
[51]
Zhengzhe Liu, Yi Wang, Xiaojuan Qi, and Chi-Wing Fu. 2022b. Towards implicit text-guided 3d shape generation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 17896–17906.
[52]
Rui Ma, Akshay Gadi Patil, Matt Fisher, Manyi Li, Soren Pirk, Binh-Son Hua, Sai-Kit Yeung, Xin Tong, Leonidas J. Guibas, and Hao Zhang. 2018. Language-Driven Synthesis of 3D Scenes Using Scene Databases. ACM Transactions on Graphics 37, 6 (2018), Article 212.
[53]
Oscar Michel, Roi Bar-On, Richard Liu, Sagie Benaim, and Rana Hanocka. 2022. Text2Mesh: Text-Driven Neural Stylization for Meshes. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 13492–13502.
[54]
Paritosh Mittal, Yen-Chi Cheng, Maneesh Singh, and Shubham Tulsiani. 2022. Autosdf: Shape priors for 3d completion, reconstruction and generation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 306–315.
[55]
Kaichun Mo, Shilin Zhu, Angel X Chang, Li Yi, Subarna Tripathi, Leonidas J Guibas, and Hao Su. 2019. Partnet: A large-scale benchmark for fine-grained and hierarchical part-level 3d object understanding. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 909–918.
[56]
Luke Olsen, Faramarz F. Samavati, Mario Costa Sousa, and Joaquim A. Jorge. 2009. Sketch-based modeling: A survey. Computers & Graphics 33 (2009), 85–103. Issue 1.
[57]
Maks Ovsjanikov, Wilmot Li, Leonidas J. Guibas, and Niloy J. Mitra. 2011. Exploration of continuous variability in collections of 3D shapes. ACM Transactions on Graphics 30, 4 (2011).
[58]
Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Lovegrove. 2019. DeepSDF: Learning continuous signed distance functions for shape representation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 165–174.
[59]
Or Patashnik, Zongze Wu, Eli Shechtman, Daniel Cohen-Or, and Dani Lischinski. 2021. Styleclip: Text-driven manipulation of stylegan imagery. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2085–2094.
[60]
Ofek Pearl, Itai Lang, Yuhua Hu, Raymond A. Yeh, and Rana Hanocka. 2022. GeoCode: Interpretable Shape Programs. (2022).
[61]
Songyou Peng, Chiyu “Max” Jiang, Yiyi Liao, Michael Niemeyer, Marc Pollefeys, and Andreas Geiger. 2021. Shape As Points: A Differentiable Poisson Solver. In Conference on Neural Information Processing Systems (NeurIPS).
[62]
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. 2022. DreamFusion: Text-to-3D using 2D Diffusion. In International Conference on Learning Representations (ICLR).
[63]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, 2021. Learning transferable visual models from natural language supervision. In Proceedings of International Conference on Machine Learning (ICML). 8748–8763.
[64]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. 2022. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 (2022).
[65]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 10684–10695.
[66]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, 2022. Photorealistic text-to-image diffusion models with deep language understanding. Conference on Neural Information Processing Systems (NeurIPS) 35 (2022), 36479–36494.
[67]
Aditya Sanghi, Hang Chu, Joseph G Lambourne, Ye Wang, Chin-Yi Cheng, Marco Fumero, and Kamal Rahimi Malekshan. 2022. Clip-forge: Towards zero-shot text-to-shape generation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 18603–18613.
[68]
Yujun Shen, Jinjin Gu, Xiaoou Tang, and Bolei Zhou. 2020. Interpreting the latent space of gans for semantic face editing. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 9243–9252.
[69]
Yujun Shen and Bolei Zhou. 2021. Closed-form factorization of latent semantics in gans. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 1532–1540.
[70]
Edward J. Smith and David Meger. 2017. Improved adversarial systems for 3D object generation and reconstruction. In Conference on Robot Learning. PMLR, 87–96.
[71]
Omer Tov, Yuval Alaluf, Yotam Nitzan, Or Patashnik, and Daniel Cohen-Or. 2021. Designing an Encoder for StyleGAN Image Manipulation. In ACM Transactions on Graphics (SIGGRAPH), Vol. 40. 1–14.
[72]
Nobuyuki Umetani, Takeo Igarashi, and Niloy J. Mitra. 2012. Guided exploration of physically valid shapes for furniture design. ACM Transactions on Graphics 31, 4 (2012), 86:1–86:11.
[73]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Conference on Neural Information Processing Systems (NeurIPS) 30 (2017).
[74]
Andrey Voynov and Artem Babenko. 2020. Unsupervised discovery of interpretable directions in the gan latent space. In Proceedings of International Conference on Machine Learning (ICML). 9786–9796.
[75]
Nanyang Wang, Yinda Zhang, Zhuwen Li, Yanwei Fu, Wei Liu, and Yu-Gang Jiang. 2018. Pixel2Mesh: Generating 3D mesh models from single RGB images. In European Conference on Computer Vision (ECCV). 52–67.
[76]
Yuxiang Wei, Yupeng Shi, Xiao Liu, Zhilong Ji, Yuan Gao, Zhongqin Wu, and Wangmeng Zuo. 2021. Orthogonal jacobian regularization for unsupervised disentanglement in image generation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 6721–6730.
[77]
Jiajun Wu, Chengkai Zhang, Tianfan Xue, Bill Freeman, and Josh Tenenbaum. 2016. Learning a probabilistic latent space of object shapes via 3D generative-adversarial modeling. In Conference on Neural Information Processing Systems (NeurIPS). 82–90.
[78]
Weihao Xia, Yujiu Yang, Jing-Hao Xue, and Baoyuan Wu. 2021. Tedigan: Text-guided diverse face image generation and manipulation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2256–2265.
[79]
Jianwen Xie, Yifei Xu, Zilong Zheng, Song-Chun Zhu, and Ying Nian Wu. 2021. Generative pointnet: Deep energy-based learning on unordered point sets for 3d generation, reconstruction and classification. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 14976–14985.
[80]
Kai Xu, Hao Zhang, Daniel Cohen-Or, and Baoquan Chen. 2012. Fit and Diverse: Set Evolution for Inspiring 3D Shape Galleries. ACM Transactions on Graphics 31, 4 (2012), 57:1–57:10.
[81]
Yong-Liang Yang, Yi-Jun Yang, Helmut Pottmann, and Niloy J. Mitra. 2011. Shape space exploration of constrained meshes. ACM Transactions on Graphics 30, 6 (2011).
[82]
Xiaohui Zeng, Arash Vahdat, Francis Williams, Zan Gojcic, Or Litany, Sanja Fidler, and Karsten Kreis. 2022. LION: Latent Point Diffusion Models for 3D Shape Generation. In Conference on Neural Information Processing Systems (NeurIPS).
[83]
Biao Zhang, Matthias Nießner, and Peter Wonka. 2022b. 3DILG: Irregular latent grids for 3d generative modeling. Conference on Neural Information Processing Systems (NeurIPS) (2022).
[84]
Renrui Zhang, Ziyu Guo, Wei Zhang, Kunchang Li, Xupeng Miao, Bin Cui, Yu Qiao, Peng Gao, and Hongsheng Li. 2022a. Pointclip: Point cloud understanding by clip. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 8552–8562.
[85]
Song-Hai Zhang, Yuan-Chen Guo, and Qing-Wen Gu. 2021. Sketch2model: View-aware 3d modeling from single free-hand sketches. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 6012–6021.
[86]
Zibo Zhao, Wen Liu, Xin Chen, Xianfang Zeng, Rui Wang, Pei Cheng, Bin Fu, Tao Chen, Gang Yu, and Shenghua Gao. 2023. Michelangelo: Conditional 3D Shape Generation based on Shape-Image-Text Aligned Latent Representation. (2023).
[87]
Xin-Yang Zheng, Yang Liu, Peng-Shuai Wang, and Xin Tong. 2022. SDF-StyleGAN: Implicit SDF-Based StyleGAN for 3D Shape Generation. In Eurographics Symposium on Geometry Processing (SGP).
[88]
Xin-Yang Zheng, Hao Pan, Peng-Shuai Wang, Xin Tong, Yang Liu, and Heung-Yeung Shum. 2023. Locally Attentional SDF Diffusion for Controllable 3D Shape Generation. ACM Transactions on Graphics (SIGGRAPH) 42, 4 (2023).
[89]
Youyi Zheng, Han Liu, Julie Dorsey, and Niloy J. Mitra. 2016. Ergonomics-Inspired Reshaping and Exploration of Collections of Models. IEEE Transactions Visualization Computer Graphics 22, 6 (2016), 1732–1744.
[90]
Yue Zhong, Yonggang Qi, Yulia Gryaditskaya, Honggang Zhang, and Yi-Zhe Song. 2020. Towards practical sketch-based 3d shape generation: The role of professional sketches. IEEE Transactions on Circuits and Systems for Video Technology 31, 9 (2020), 3518–3528.
[91]
Qian-Yi Zhou, Jaesik Park, and Vladlen Koltun. 2018. Open3D: A Modern Library for 3D Data Processing. arXiv:1801.09847 (2018).
[92]
Xiangyang Zhu, Renrui Zhang, Bowei He, Ziyao Zeng, Shanghang Zhang, and Peng Gao. 2022. PointCLIP V2: Adapting CLIP for Powerful 3D Open-world Learning. arXiv preprint arXiv:2211.11682 (2022).