
“An Implicit Physical Face Model Driven by Expression and Style” by Yang, Zoss, Chandran, Gotardo, Gross, et al. …
Conference:
Type(s):
Title:
- An Implicit Physical Face Model Driven by Expression and Style
Session/Category Title:
- Head & Face
Presenter(s)/Author(s):
Abstract:
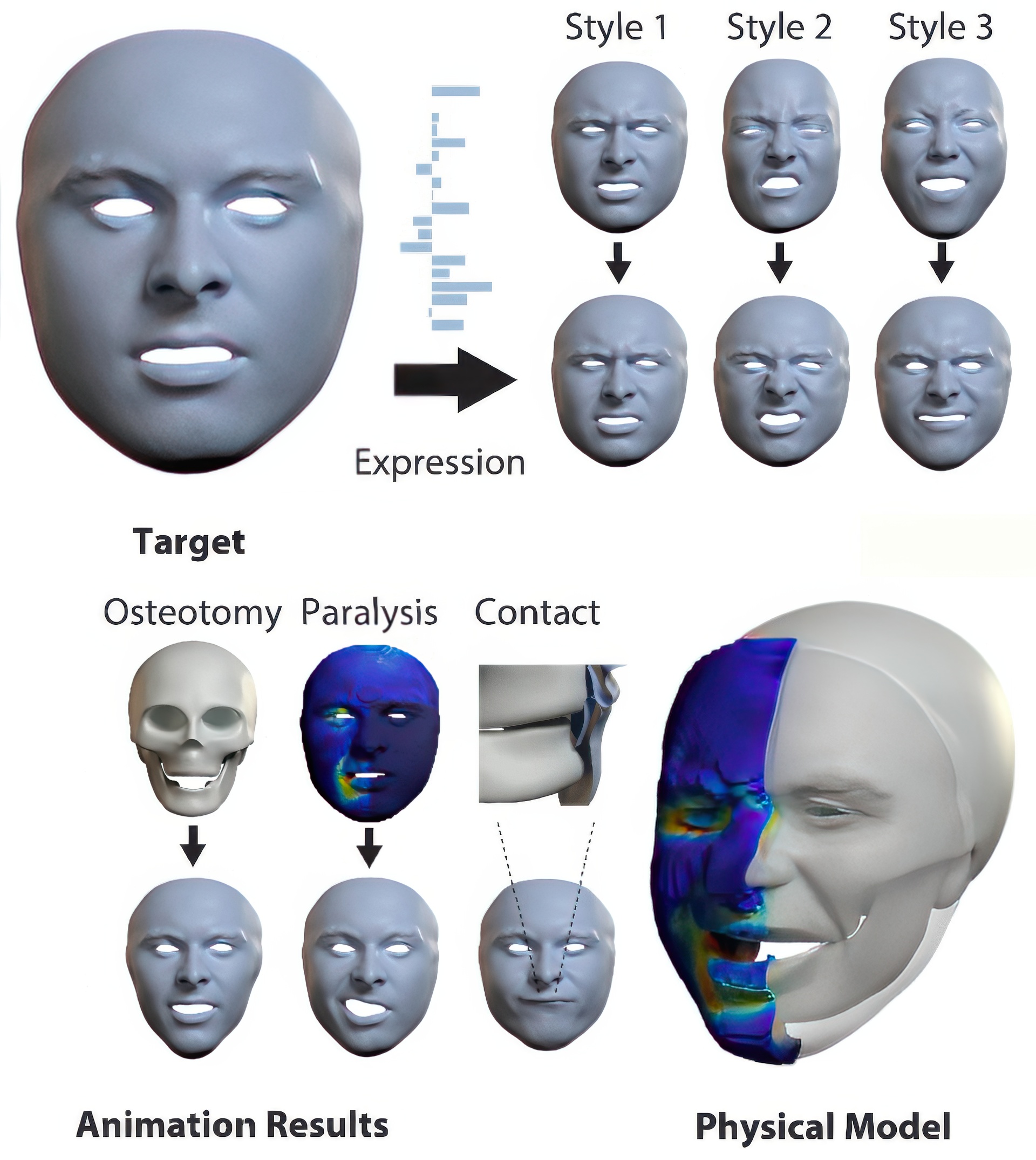
3D facial animation is often produced by manipulating facial deformation models (or rigs), that are traditionally parameterized by expression controls. A key component that is usually overlooked is expression “style”, as in, how a particular expression is performed. Although it is common to define a semantic basis of expressions that characters can perform, most characters perform each expression in their own style. To date, style is usually entangled with the expression, and it is not possible to transfer the style of one character to another when considering facial animation. We present a new face model, based on a data-driven implicit neural physics model, that can be driven by both expression and style separately. At the core, we present a framework for learning implicit physics-based actuations for multiple subjects simultaneously, trained on a few arbitrary performance capture sequences from a small set of identities. Once trained, our method allows generalized physics-based facial animation for any of the trained identities, extending to unseen performances. Furthermore, it grants control over the animation style, enabling style transfer from one character to another or blending styles of different characters. Lastly, as a physics-based model, it is capable of synthesizing physical effects, such as collision handling, setting our method apart from conventional approaches.
References:
[1]
Kfir Aberman, Yijia Weng, Dani Lischinski, Daniel Cohen-Or, and Baoquan Chen. 2020. Unpaired Motion Style Transfer from Video to Animation. ACM Transactions on Graphics (TOG) 39, 4 (2020), 64.
[2]
ShahRukh Athar, Zexiang Xu, Kalyan Sunkavalli, Eli Shechtman, and Zhixin Shu. 2022. Rignerf: Fully controllable neural 3d portraits. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition. 20364–20373.
[3]
Ziqian Bai, Zhaopeng Cui, Xiaoming Liu, and Ping Tan. 2021. Riggable 3d face reconstruction via in-network optimization. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 6216–6225.
[4]
Thambiraja Balamurugan, Ikhsanul Habibie, Sadegh Aliakbarian, Darren Cosker, Christian Theobalt, and Justus Thies. 2022. Imitator: Personalized Speech-driven 3D Facial Animation. arXiv.
[5]
Michael Bao, Matthew Cong, Stéphane Grabli, and Ronald Fedkiw. 2018. High-Quality Face Capture Using Anatomical Muscles. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (12 2018). http://arxiv.org/abs/1812.02836
[6]
Vincent Barrielle, Nicolas Stoiber, and Cédric Cagniart. 2016. BlendForces: A Dynamic Framework for Facial Animation. Computer Graphics Forum (2016). https://doi.org/10.1111/cgf.12836
[7]
Kiran S. Bhat, Rony Goldenthal, Yuting Ye, Ronald Mallet, and Michael Koperwas. 2013. High Fidelity Facial Animation Capture and Retargeting with Contours. In Proceedings of the 12th ACM SIGGRAPH/Eurographics Symposium on Computer Animation. Association for Computing Machinery, 7–14.
[8]
Sofien Bouaziz, Sebastian Martin, Tiantian Liu, Ladislav Kavan, and Mark Pauly. 2014. Projective dynamics: fusing constraint projections for fast simulation. ACM Transactions on Graphics 33, 4 (7 2014), 1–11. https://doi.org/10.1145/2601097.2601116
[9]
Sofien Bouaziz, Yangang Wang, and Mark Pauly. 2013. Online Modeling for Realtime Facial Animation. 32, 4, Article 40 (2013).
[10]
Chen Cao, Qiming Hou, and Kun Zhou. 2014. Displaced Dynamic Expression Regression for Real-Time Facial Tracking and Animation. 33, 4, Article 43 (2014).
[11]
Prashanth Chandran, Derek Bradley, Markus Gross, and Thabo Beeler. 2020. Semantic Deep Face Models. (2020), 345–354.
[12]
Prashanth Chandran, Loïc Ciccone, Markus Gross, and Derek Bradley. 2022a. Local Anatomically-Constrained Facial Performance Retargeting. ACM Trans. Graph. 41, 4, Article 168 (jul 2022).
[13]
Prashanth Chandran, Gaspard Zoss, Markus Gross, Paulo Gotardo, and Derek Bradley. 2022b. Facial Animation with Disentangled Identity, Motion using Transformers. (2022).
[14]
Bindita Chaudhuri, Noranart Vesdapunt, and Baoyuan Wang. 2019. Joint face detection and facial motion retargeting for multiple faces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9719–9728.
[15]
Byungkuk Choi, Haekwang Eom, Benjamin Mouscadet, Stephen Cullingford, Kurt Ma, Stefanie Gassel, Suzi Kim, Andrew Moffat, Millicent Maier, Marco Revelant, Joe Letteri, and Karan Singh. 2022. Animatomy: An Animator-Centric, Anatomically Inspired System for 3D Facial Modeling, Animation and Transfer. In SIGGRAPH Asia 2022 Conference Papers. Association for Computing Machinery, Article 16, 9 pages.
[16]
Timothy Costigan, Mukta Prasad, and Rachel McDonnell. 2014. Facial Retargeting Using Neural Networks. Association for Computing Machinery, 31–38.
[17]
D. Cudeiro, T. Bolkart, C. Laidlaw, A. Ranjan, and M. J. Black. 2019. Capture, Learning, and Synthesis of 3D Speaking Styles. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 10093–10103.
[18]
Daniel K. Dorda, Daniel Peter, Dominik Borer, Niko Benjamin Huber, Irena Sailer, Markus Gross, Barbara Solenthaler, and Bernhard Thomaszewski. 2022. Differentiable Simulation for Outcome-Driven Orthognathic Surgery Planning. In Proc. ACM SIGGRAPH/Eurographics Symposium on Computer Animation.
[19]
Tao Du, Kui Wu, Pingchuan Ma, Sebastien Wah, Andrew Spielberg, Daniela Rus, and Wojciech Matusik. 2022. DiffPD: Differentiable Projective Dynamics. ACM Transactions on Graphics 41, 2 (4 2022), 1–21. https://doi.org/10.1145/3490168
[20]
Bernhard Egger, William AP Smith, Ayush Tewari, Stefanie Wuhrer, Michael Zollhoefer, Thabo Beeler, Florian Bernard, Timo Bolkart, Adam Kortylewski, Sami Romdhani, 2020. 3d morphable face models—past, present, and future. ACM Transactions on Graphics (ToG) 39, 5 (2020), 1–38.
[21]
Xun Huang and Serge Belongie. 2017. Arbitrary Style Transfer in Real-Time With Adaptive Instance Normalization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV).
[22]
Alexandru-Eugen Ichim, Petr Kadleček, Ladislav Kavan, and Mark Pauly. 2017. Phace: Physics-based Face Modeling and Animation. ACM Transactions on Graphics 36, 4 (7 2017), 1–14. https://doi.org/10.1145/3072959.3073664
[23]
Alexandru-Eugen Ichim, Ladislav Kavan, Merlin Nimier-David, and Mark Pauly. 2016. Building and Animating User-Specific Volumetric Face Rigs. In Proceedings of the ACM SIGGRAPH/Eurographics Symposium on Computer Animation. Eurographics Association, 107–117.
[24]
Deok-Kyeong Jang, Soomin Park, and Sung-Hee Lee. 2022. Motion Puzzle: Arbitrary Motion Style Transfer by Body Part. ACM Trans. Graph. 41, 3, Article 33 (2022).
[25]
Yongcheng Jing, Xiao Liu, Yukang Ding, Xinchao Wang, Errui Ding, Mingli Song, and Shilei Wen. 2020. Dynamic Instance Normalization for Arbitrary Style Transfer. In AAAI.
[26]
Yongcheng Jing, Yezhou Yang, Zunlei Feng, Jingwen Ye, Yizhou Yu, and Mingli Song. 2019. Neural Style Transfer: A Review. IEEE Transactions on Visualization and Computer Graphics.
[27]
Petr Kadleček and Ladislav Kavan. 2019. Building Accurate Physics-based Face Models from Data. Proceedings of the ACM on Computer Graphics and Interactive Techniques 2, 2 (7 2019), 1–16. https://doi.org/10.1145/3340256
[28]
D. Kim, T. Kuang, Y. L. Rodrigues, J. Gateno, S. G. F. Shen, X. Wang, H. Deng, P. Yuan, D. M. Alfi, M. A. K. Liebschner, and J. J. Xia. 2019. A New Approach of Predicting Facial Changes following Orthognathic Surgery using Realistic Lip Sliding Effect. In Proc. MICCAI.
[29]
Paul Hyunjin Kim, Yeongho Seol, Jaewon Song, and Junyong Noh. 2011. Facial Retargeting by Adding Supplemental Blendshapes. In Pacific Graphics Short Papers, Bing-Yu Chen, Jan Kautz, Tong-Yee Lee, and Ming C. Lin (Eds.). The Eurographics Association.
[30]
Seonghyeon Kim, Sunjin Jung, Kwanggyoon Seo, Roger Blanco i Ribera, and Junyong Noh. 2021. Deep Learning-Based Unsupervised Human Facial Retargeting. Computer Graphics Forum 40, 7 (2021), 45–55.
[31]
Gergely Klár, Andrew Moffat, Ken Museth, and Eftychios Sifakis. 2020. Shape Targeting: A Versatile Active Elasticity Constitutive Model. In ACM SIGGRAPH 2020 Talks (Virtual Event, USA) (SIGGRAPH ’20). Association for Computing Machinery, New York, NY, USA, Article 59, 2 pages. https://doi.org/10.1145/3388767.3407379
[32]
Avisek Lahiri, Vivek Kwatra, Christian Frueh, John Lewis, and Chris Bregler. 2021. LipSync3D: Data-Efficient Learning of Personalized 3D Talking Faces From Video Using Pose and Lighting Normalization. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
[33]
J P Lewis, Ken Anjyo, Taehyun Rhee, Mengjie Zhang, Fred Pighin, and Zhigang Deng. 2014. Practice and Theory of Blendshape Facial Models. In Eurographics 2014 – State of the Art Reports, Sylvain Lefebvre and Michela Spagnuolo (Eds.). The Eurographics Association. https://doi.org/10.2312/egst.20141042
[34]
Hao Li, Jihun Yu, Yuting Ye, and Chris Bregler. 2013. Realtime Facial Animation with On-the-Fly Correctives. 32, 4, Article 42 (2013).
[35]
Minchen Li, Zachary Ferguson, Teseo Schneider, Timothy R Langlois, Denis Zorin, Daniele Panozzo, Chenfanfu Jiang, and Danny M Kaufman. 2020. Incremental potential contact: intersection-and inversion-free, large-deformation dynamics.ACM Trans. Graph. 39, 4 (2020), 49.
[36]
Hsueh-Ti Derek Liu, Francis Williams, Alec Jacobson, Sanja Fidler, and Or Litany. 2022. Learning Smooth Neural Functions via Lipschitz Regularization. arXiv preprint arXiv:2202.08345 (2022).
[37]
Ko-Yun Liu, Wan-Chun Ma, Chun-Fa Chang, Chuan-Chang Wang, and Paul Debevec. 2011. A framework for locally retargeting and rendering facial performance. Computer Animation and Virtual Worlds 22, 2-3 (2011), 159–167.
[38]
Lucio Moser, Chinyu Chien, Mark Williams, Jose Serra, Darren Hendler, and Doug Roble. 2021. Semi-Supervised Video-Driven Facial Animation Transfer for Production. 40, 6, Article 222 (2021).
[39]
Jun-yong Noh and Ulrich Neumann. 2001. Expression Cloning. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques(SIGGRAPH ’01). Association for Computing Machinery, 277–288.
[40]
Keunhong Park, Utkarsh Sinha, Jonathan T Barron, Sofien Bouaziz, Dan B Goldman, Steven M Seitz, and Ricardo Martin-Brualla. 2021b. Nerfies: Deformable neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 5865–5874.
[41]
Soomin Park, Deok-Kyeong Jang, and Sung-Hee Lee. 2021a. Diverse Motion Stylization for Multiple Style Domains via Spatial-Temporal Graph-Based Generative Model. Proc. ACM Comput. Graph. Interact. Tech. 4, 3, Article 36 (2021).
[42]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32. 8024–8035. http://papers.neurips.cc/paper/9015-pytorch-an-imperative-style-high-performance-deep-learning-library.pdf
[43]
Trong-Thang Pham, Nhat Le, Tuong Do, Hung Nguyen, Erman Tjiputra, Quang D. Tran, and Anh Nguyen. 2023. Style Transfer for 2D Talking Head Animation. arxiv:2303.09799 [cs.CV]
[44]
Roger Blanco i Ribera, Eduard Zell, J. P. Lewis, Junyong Noh, and Mario Botsch. 2017. Facial Retargeting with Automatic Range of Motion Alignment. ACM Trans. Graph. 36, 4, Article 154 (2017).
[45]
Alexander Richard, Michael Zollhöfer, Yandong Wen, Fernando de la Torre, and Yaser Sheikh. 2021. MeshTalk: 3D Face Animation From Speech Using Cross-Modality Disentanglement. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 1173–1182.
[46]
Yeongho Seol, J.P. Lewis, Jaewoo Seo, Byungkuk Choi, Ken Anjyo, and Junyong Noh. 2012. Spacetime Expression Cloning for Blendshapes. 31, 2, Article 14 (apr 2012).
[47]
Yeongho Seol, Jaewoo Seo, Hyunjin Kim, J.P. Lewis, and Junyong Noh. 2011. Artist Friendly Facial Animation Retargeting. 30 (12 2011), 162.
[48]
Eftychios Sifakis, Igor Neverov, and Ronald Fedkiw. 2005. Automatic determination of facial muscle activations from sparse motion capture marker data. ACM Transactions on Graphics 24, 3 (7 2005), 417–425. https://doi.org/10.1145/1073204.1073208
[49]
Jaewon Song, Byungkuk Choi, Yeongho Seol, and Junyong Noh. 2011. Characteristic Facial Retargeting. Comput. Animat. Virtual Worlds 22, 2–3 (2011), 187–194.
[50]
Sangeetha Grama Srinivasan, Qisi Wang, Junior Rojas, Gergely Klár, Ladislav Kavan, and Eftychios Sifakis. 2021. Learning active quasistatic physics-based models from data. ACM Transactions on Graphics 40, 4 (8 2021), 1–14. https://doi.org/10.1145/3450626.3459883
[51]
Robert W. Sumner and Jovan Popović. 2004. Deformation Transfer for Triangle Meshes. 23, 3 (2004), 399–405.
[52]
Supasorn Suwajanakorn, Steven M. Seitz, and Ira Kemelmacher-Shlizerman. 2017. Synthesizing Obama: Learning Lip Sync from Audio. ACM Trans. Graph. 36, 4, Article 95 (2017).
[53]
T. Tao, X. Zhan, Z. Chen, and M. van de Panne. 2022. Style-ERD: Responsive and Coherent Online Motion Style Transfer. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 6583–6593.
[54]
Daoye Wang, Prashanth Chandran, Gaspard Zoss, Derek Bradley, and Paulo Gotardo. 2022. Morf: Morphable radiance fields for multiview neural head modeling. In ACM SIGGRAPH 2022 Conference Proceedings. 1–9.
[55]
Feng Xu, Jinxiang Chai, Yilong Liu, and Xin Tong. 2014. Controllable High-Fidelity Facial Performance Transfer. ACM Trans. Graph. 33, 4, Article 42 (2014).
[56]
Lingchen Yang, Byungsoo Kim, Gaspard Zoss, Baran Gözcü, Markus Gross, and Barbara Solenthaler. 2022. Implicit neural representation for physics-driven actuated soft bodies. ACM Transactions on Graphics (TOG) 41, 4 (2022), 1–10.
[57]
Juyong Zhang, Keyu Chen, and Jianmin Zheng. 2022. Facial Expression Retargeting From Human to Avatar Made Easy. IEEE Transactions on Visualization and Computer Graphics 28, 2 (2022), 1274–1287.
[58]
Yang Zhou, Xintong Han, Eli Shechtman, Jose Echevarria, Evangelos Kalogerakis, and Dingzeyu Li. 2020. MakeltTalk: Speaker-Aware Talking-Head Animation. ACM Trans. Graph. 39, 6, Article 221 (2020).
[59]
Gaspard Zoss, Thabo Beeler, Markus Gross, and Derek Bradley. 2019. Accurate markerless jaw tracking for facial performance capture. ACM Transactions on Graphics 38, 4 (7 2019), 1–8. https://doi.org/10.1145/3306346.3323044