
“360° Reconstruction From a Single Image Using Space Carved Outpainting” by Ryu, Gong, Kim, Lee and Cho
Conference:
Type(s):
Title:
- 360° Reconstruction From a Single Image Using Space Carved Outpainting
Session/Category Title:
- Reconstruction
Presenter(s)/Author(s):
Abstract:
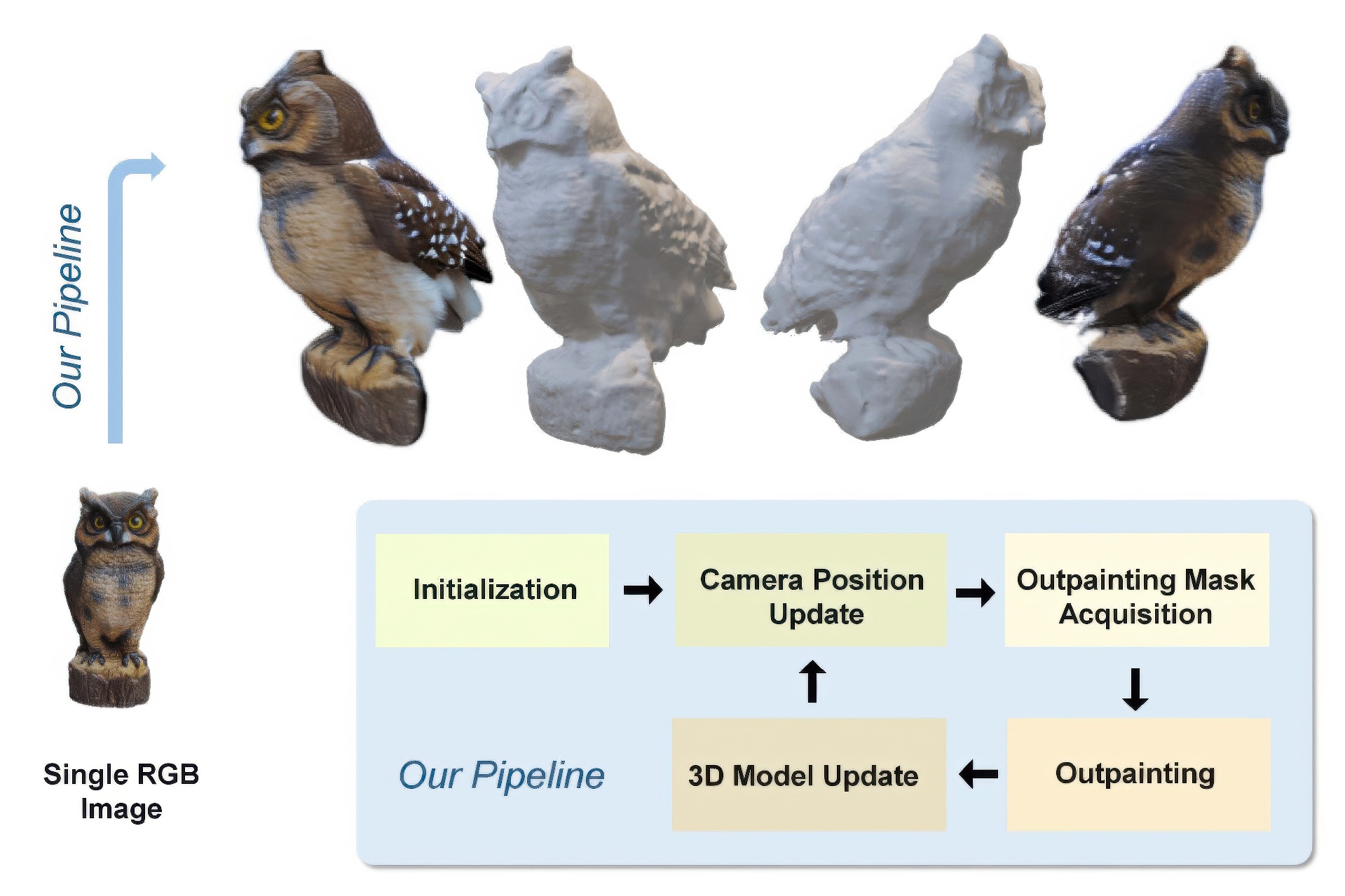
We introduce POP3D, a novel framework that creates a full $360^\circ$-view 3D model from a single image. POP3D resolves two prominent issues that limit the single-view reconstruction. Firstly, POP3D offers substantial generalizability to arbitrary categories, a trait that previous methods struggle to achieve. Secondly, POP3D further improves reconstruction fidelity and naturalness, a crucial aspect that concurrent works fall short of. POP3D marries the strengths of four primary components: (1) a monocular depth and normal predictor that serves to predict crucial geometric cues, (2) a space carving method capable of demarcating the potentially unseen portions of the target object, (3) a generative model pre-trained on a large-scale image dataset that can complete unseen regions of the target, and (4) a neural implicit surface reconstruction method tailored in reconstructing objects using RGB images along with monocular geometric cues. The combination of these components enables POP3D to readily generalize across various in-the-wild images and generate state-of-the-art reconstructions, outperforming similar works by a significant margin.
References:
[1]
Matan Atzmon and Yaron Lipman. 2020. SAL: Sign Agnostic Learning of Shapes From Raw Data. In Proc. of CVPR.
[2]
Jonathan T. Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P. Srinivasan. 2021. Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields. In Proc. of ICCV.
[3]
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. 2022. Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields. In Proc. of CVPR.
[4]
Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter Wonka, and Matthias Müller. 2023. ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth. arxiv:2302.12288 [cs.CV]
[5]
Eric R. Chan, Koki Nagano, Matthew A. Chan, Alexander W. Bergman, Jeong Joon Park, Axel Levy, Miika Aittala, Shalini De Mello, Tero Karras, and Gordon Wetzstein. 2023. Generative Novel View Synthesis with 3D-Aware Diffusion Models. arxiv:2304.02602 [cs.CV]
[6]
Christopher B Choy, Danfei Xu, JunYoung Gwak, Kevin Chen, and Silvio Savarese. 2016. 3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction. In Proc. of ECCV.
[7]
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. 2022. Objaverse: A Universe of Annotated 3D Objects. arxiv:2212.08051 [cs.CV]
[8]
Congyue Deng, Chiyu “Max” Jiang, Charles R. Qi, Xinchen Yan, Yin Zhou, Leonidas Guibas, and Dragomir Anguelov. 2023. NeRDi: Single-View NeRF Synthesis With Language-Guided Diffusion As General Image Priors. In Proc. of CVPR. 20637–20647.
[9]
Ainaz Eftekhar, Alexander Sax, Jitendra Malik, and Amir Zamir. 2021. Omnidata: A Scalable Pipeline for Making Multi-Task Mid-Level Vision Datasets From 3D Scans. In Proc. of ICCV. 10786–10796.
[10]
P. Favaro and S. Soatto. 2005. A geometric approach to shape from defocus. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI) 27, 3 (2005), 406–417.
[11]
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit Haim Bermano, Gal Chechik, and Daniel Cohen-or. 2023. An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion. In Proc. of ICLR.
[12]
R. Girdhar, D.F. Fouhey, M. Rodriguez, and A. Gupta. 2016. Learning a Predictable and Generative Vector Representation for Objects. In Proc. of ECCV.
[13]
Thibault Groueix, Matthew Fisher, Vladimir G. Kim, Bryan Russell, and Mathieu Aubry. 2018. AtlasNet: A Papier-Mâché Approach to Learning 3D Surface Generation. In Proc. of CVPR.
[14]
Jiatao Gu, Alex Trevithick, Kai-En Lin, Josh Susskind, Christian Theobalt, Lingjie Liu, and Ravi Ramamoorthi. 2023. NerfDiff: Single-image View Synthesis with NeRF-guided Distillation from 3D-aware Diffusion. In Proc. of ICML.
[15]
Pengsheng Guo, Miguel Angel Bautista, Alex Colburn, Liang Yang, Daniel Ulbricht, Joshua M. Susskind, and Qi Shan. 2022. Fast and Explicit Neural View Synthesis. In Proc. of WACV. 3791–3800.
[16]
Yuxuan Han, Ruicheng Wang, and Jiaolong Yang. 2022. Single-View View Synthesis in the Wild with Learned Adaptive Multiplane Images. In Proc. of ACM SIGGRAPH.
[17]
Philipp Henzler, Niloy J Mitra, and Tobias Ritschel. 2019. Escaping Plato’s Cave: 3D Shape From Adversarial Rendering. In Proc. of ICCV.
[18]
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. In Proc. of ICLR.
[19]
Lukas Höllein, Ang Cao, Andrew Owens, Justin Johnson, and Matthias Nießner. 2023. Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models. arxiv:2303.11989 [cs.CV]
[20]
Ajay Jain, Matthew Tancik, and Pieter Abbeel. 2021. Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis. In Proc. of ICCV. 5885–5894.
[21]
Wonbong Jang and Lourdes Agapito. 2021. CodeNeRF: Disentangled Neural Radiance Fields for Object Categories. In Proc. of ICCV. 12949–12958.
[22]
Angjoo Kanazawa, Shubham Tulsiani, Alexei A. Efros, and Jitendra Malik. 2018. Learning Category-Specific Mesh Reconstruction from Image Collections. In Proc. of ECCV.
[23]
Animesh Karnewar, Andrea Vedaldi, David Novotny, and Niloy J. Mitra. 2023. HOLODIFFUSION: Training a 3D Diffusion Model Using 2D Images. In Proc. of CVPR. 18423–18433.
[24]
K.N. Kutulakos and S.M. Seitz. 1999. A theory of shape by space carving. In Proc. of ICCV. 307–314 vol.1.
[25]
A. Laurentini. 1994. The Visual Hull Concept for Silhouette-Based Image Understanding. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI) 16, 2 (1994), 150–162.
[26]
Min Seok Lee, WooSeok Shin, and Sung Won Han. 2022. TRACER: Extreme Attention Guided Salient Object Tracing Network. In Proc. of AAAI Conference on Artificial Intelligence, Vol. 36. 12993–12994.
[27]
Kai-En Lin, Yen-Chen Lin, Wei-Sheng Lai, Tsung-Yi Lin, Yi-Chang Shih, and Ravi Ramamoorthi. 2023. Vision Transformer for NeRF-Based View Synthesis From a Single Input Image. In Proc. of WACV. 806–815.
[28]
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl Vondrick. 2023. Zero-1-to-3: Zero-shot One Image to 3D Object. arxiv:2303.11328 [cs.CV]
[29]
Angeline Loh. 2006. The recovery of 3-D structure using visual texture patterns. Ph. D. Dissertation.
[30]
Luke Melas-Kyriazi, Iro Laina, Christian Rupprecht, and Andrea Vedaldi. 2023. RealFusion: 360deg Reconstruction of Any Object From a Single Image. In Proc. of CVPR. 8446–8455.
[31]
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. 2020. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In Proc. of ECCV.
[32]
Anish Mittal, Rajiv Soundararajan, and Alan C. Bovik. 2013. Making a “Completely Blind” Image Quality Analyzer. IEEE Signal Processing Letters 20, 3 (2013), 209–212.
[33]
Alex Nichol, Heewoo Jun, Prafulla Dhariwal, Pamela Mishkin, and Mark Chen. 2022. Point-E: A System for Generating 3D Point Clouds from Complex Prompts. arxiv:2212.08751 [cs.CV]
[34]
Michael Niemeyer, Lars Mescheder, Michael Oechsle, and Andreas Geiger. 2020. Differentiable Volumetric Rendering: Learning Implicit 3D Representations without 3D Supervision. In Proc. of CVPR.
[35]
Dario Pavllo, David Joseph Tan, Marie-Julie Rakotosaona, and Federico Tombari. 2023. Shape, Pose, and Appearance from a Single Image via Bootstrapped Radiance Field Inversion. In Proc. of CVPR.
[36]
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. 2023. DreamFusion: Text-to-3D using 2D Diffusion. In Proc. of ICLR.
[37]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. In Proc. of ICML, Vol. 139. 8748–8763.
[38]
Amit Raj, Srinivas Kaza, Ben Poole, Michael Niemeyer, Nataniel Ruiz, Ben Mildenhall, Shiran Zada, Kfir Aberman, Michael Rubinstein, Jonathan Barron, Yuanzhen Li, and Varun Jampani. 2023. DreamBooth3D: Subject-Driven Text-to-3D Generation. arxiv:2303.13508 [cs.CV]
[39]
Barbara Roessle, Jonathan T. Barron, Ben Mildenhall, Pratul P. Srinivasan, and Matthias Nießner. 2022. Dense Depth Priors for Neural Radiance Fields from Sparse Input Views. In Proc. of CVPR.
[40]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-Resolution Image Synthesis With Latent Diffusion Models. In Proc. of CVPR. 10684–10695.
[41]
Radu Alexandru Rosu and Sven Behnke. 2023. PermutoSDF: Fast Multi-View Reconstruction With Implicit Surfaces Using Permutohedral Lattices. In Proc. of CVPR. 8466–8475.
[42]
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. 2023. DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation. In Proc. of CVPR. 22500–22510.
[43]
Shunsuke Saito, Zeng Huang, Ryota Natsume, Shigeo Morishima, Angjoo Kanazawa, and Hao Li. 2019. PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization. In Proc. of ICCV.
[44]
Mehdi S. M. Sajjadi, Henning Meyer, Etienne Pot, Urs Bergmann, Klaus Greff, Noha Radwan, Suhani Vora, Mario Lučić, Daniel Duckworth, Alexey Dosovitskiy, Jakob Uszkoreit, Thomas Funkhouser, and Andrea Tagliasacchi. 2022. Scene Representation Transformer: Geometry-Free Novel View Synthesis Through Set-Latent Scene Representations. In Proc. of CVPR. 6229–6238.
[45]
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade W Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, Patrick Schramowski, Srivatsa R Kundurthy, Katherine Crowson, Ludwig Schmidt, Robert Kaczmarczyk, and Jenia Jitsev. 2022. LAION-5B: An open large-scale dataset for training next generation image-text models. In Proc. of NeurIPS.
[46]
Meng-Li Shih, Shih-Yang Su, Johannes Kopf, and Jia-Bin Huang. 2020. 3D Photography using Context-aware Layered Depth Inpainting. In Proc. of CVPR.
[47]
J. Ryan Shue, Eric Ryan Chan, Ryan Po, Zachary Ankner, Jiajun Wu, and Gordon Wetzstein. 2023. 3D Neural Field Generation Using Triplane Diffusion. In Proc. of CVPR. 20875–20886.
[48]
Vincent Sitzmann, Michael Zollhöfer, and Gordon Wetzstein. 2019. Scene Representation Networks: Continuous 3D-Structure-Aware Neural Scene Representations. In Proc. of NeurIPS.
[49]
Junshu Tang, Tengfei Wang, Bo Zhang, Ting Zhang, Ran Yi, Lizhuang Ma, and Dong Chen. 2023. Make-It-3D: High-Fidelity 3D Creation from A Single Image with Diffusion Prior. arxiv:2303.14184 [cs.CV]
[50]
Kalyan Alwala Vasudev, Abhinav Gupta, and Shubham Tulsiani. 2022. Pre-train, Self-train, Distill: A simple recipe for Supersizing 3D Reconstruction. In Proc. of CVPR.
[51]
Dor Verbin, Peter Hedman, Ben Mildenhall, Todd Zickler, Jonathan T. Barron, and Pratul P. Srinivasan. 2022. Ref-NeRF: Structured View-Dependent Appearance for Neural Radiance Fields. In Proc. of CVPR.
[52]
Jianyi Wang, Zongsheng Yue, Shangchen Zhou, Kelvin C. K. Chan, and Chen Change Loy. 2023a. Exploiting Diffusion Prior for Real-World Image Super-Resolution. arxiv:2305.07015 [cs.CV]
[53]
Nanyang Wang, Yinda Zhang, Zhuwen Li, Yanwei Fu, Wei Liu, and Yu-Gang Jiang. 2018. Pixel2Mesh: Generating 3D Mesh Models from Single RGB Images. In Proc. of ECCV.
[54]
Tengfei Wang, Bo Zhang, Ting Zhang, Shuyang Gu, Jianmin Bao, Tadas Baltrusaitis, Jingjing Shen, Dong Chen, Fang Wen, Qifeng Chen, and Baining Guo. 2023b. RODIN: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion. In Proc. of CVPR. 4563–4573.
[55]
Yiming Wang, Qin Han, Marc Habermann, Kostas Daniilidis, Christian Theobalt, and Lingjie Liu. 2022. NeuS2: Fast Learning of Neural Implicit Surfaces for Multi-view Reconstruction. arxiv:2212.05231 [cs.CV]
[56]
Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli. 2004. Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing 13, 4 (2004), 600–612.
[57]
Daniel Watson, William Chan, Ricardo Martin Brualla, Jonathan Ho, Andrea Tagliasacchi, and Mohammad Norouzi. 2023. Novel View Synthesis with Diffusion Models. In Proc. of ICLR.
[58]
Chao-Yuan Wu, Justin Johnson, Jitendra Malik, Christoph Feichtenhofer, and Georgia Gkioxari. 2023a. Multiview Compressive Coding for 3D Reconstruction. In Proc. of CVPR. 9065–9075.
[59]
Shangzhe Wu, Ruining Li, Tomas Jakab, Christian Rupprecht, and Andrea Vedaldi. 2023b. MagicPony: Learning Articulated 3D Animals in the Wild. Proc. of CVPR.
[60]
Haozhe Xie, Hongxun Yao, Xiaoshuai Sun, Shangchen Zhou, and Shengping Zhang. 2019. Pix2Vox: Context-aware 3D Reconstruction from Single and Multi-view Images. In Proc. of ICCV.
[61]
Dejia Xu, Yifan Jiang, Peihao Wang, Zhiwen Fan, Yi Wang, and Zhangyang Wang. 2023. NeuralLift-360: Lifting an In-the-Wild 2D Photo to a 3D Object With 360deg Views. In Proc. of CVPR. 4479–4489.
[62]
Lior Yariv, Jiatao Gu, Yoni Kasten, and Yaron Lipman. 2021. Volume rendering of neural implicit surfaces. In Proc. of NeurIPS.
[63]
Lior Yariv, Yoni Kasten, Dror Moran, Meirav Galun, Matan Atzmon, Basri Ronen, and Yaron Lipman. 2020. Multiview Neural Surface Reconstruction by Disentangling Geometry and Appearance. In Proc. of NeurIPS.
[64]
Yufei Ye, Shubham Tulsiani, and Abhinav Gupta. 2021. Shelf-Supervised Mesh Prediction in the Wild. In Proc. of CVPR.
[65]
Alex Yu, Vickie Ye, Matthew Tancik, and Angjoo Kanazawa. 2021. pixelNeRF: Neural Radiance Fields from One or Few Images. In Proc. of CVPR.
[66]
Zehao Yu, Songyou Peng, Michael Niemeyer, Torsten Sattler, and Andreas Geiger. 2022. MonoSDF: Exploring Monocular Geometric Cues for Neural Implicit Surface Reconstruction. In Proc. of NeurIPS.
[67]
Jingbo Zhang, Xiaoyu Li, Ziyu Wan, Can Wang, and Jing Liao. 2023. Text2NeRF: Text-Driven 3D Scene Generation with Neural Radiance Fields. arxiv:2305.11588 [cs.CV]
[68]
Kai Zhang, Gernot Riegler, Noah Snavely, and Vladlen Koltun. 2020. NeRF++: Analyzing and Improving Neural Radiance Fields.
[69]
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. 2018. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proc. of CVPR.
[70]
Ruo Zhang, Ping-Sing Tsai, J.E. Cryer, and M. Shah. 1999. Shape-from-shading: a survey. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI) 21, 8 (1999), 690–706.
[71]
Zhizhuo Zhou and Shubham Tulsiani. 2023. SparseFusion: Distilling View-Conditioned Diffusion for 3D Reconstruction. In Proc. of CVPR. 12588–12597.