
“ICARUS: A Specialized Architecture for Neural Radiance Fields Rendering” by Rao, Yu, Wan, Zhou, Zheng, et al. …
Conference:
Type(s):
Title:
- ICARUS: A Specialized Architecture for Neural Radiance Fields Rendering
Session/Category Title:
- Rendering Systems
Presenter(s)/Author(s):
Abstract:
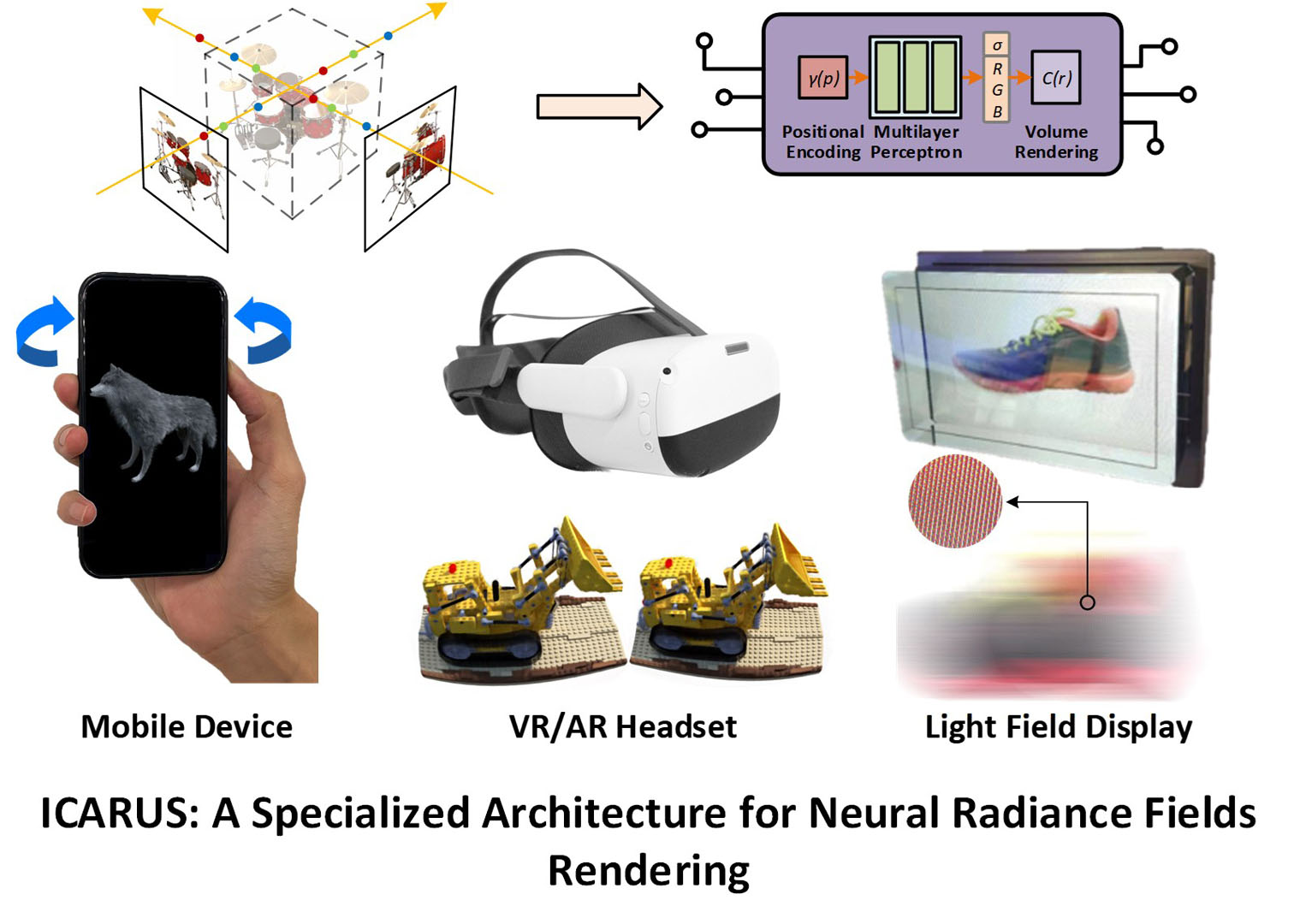
The practical deployment of Neural Radiance Fields (NeRF) in rendering applications faces several challenges, with the most critical one being low rendering speed on even high-end graphic processing units (GPUs). In this paper, we present ICARUS, a specialized accelerator architecture tailored for NeRF rendering. Unlike GPUs using general purpose computing and memory architectures for NeRF, ICARUS executes the complete NeRF pipeline using dedicated plenoptic cores (PLCore) consisting of a positional encoding unit (PEU), a multi-layer perceptron (MLP) engine, and a volume rendering unit (VRU). A PLCore takes in positions & directions and renders the corresponding pixel colors without any intermediate data going off-chip for temporary storage and exchange, which can be time and power consuming. To implement the most expensive component of NeRF, i.e., the MLP, we transform the fully connected operations to approximated reconfigurable multiple constant multiplications (MCMs), where common subexpressions are shared across different multiplications to improve the computation efficiency. We build a prototype ICARUS using Synopsys HAPS-80 S104, a field programmable gate array (FPGA)-based prototyping system for large-scale integrated circuits and systems design. We evaluate the power-performancearea (PPA) of a PLCore using 40nm LP CMOS technology. Working at 400 MHz, a single PLCore occupies 16.5 mm2 and consumes 282.8 mW, translating to 0.105 uJ/sample. The results are compared with those of GPU and tensor processing unit (TPU) implementations.
References:
1. Tomas Akenine-Möller, Eric Haines, and Naty Hoffman. 2019. Real-time rendering. Crc Press.
2. Mike Bailey. 2007. Glsl geometry shaders. Oregon State University (2007).
3. Chris Buehler, Michael Bosse, Leonard McMillan, Steven Gortler, and Michael Cohen. 2001. Unstructured lumigraph rendering. In Proceedings of the 28th annual conference on Computer graphics and interactive techniques. 425–432.
4. Edwin Earl Catmull. 1974. A subdivision algorithm for computer display of curved surfaces. The University of Utah.
5. Anpei Chen, Minye Wu, Yingliang Zhang, Nianyi Li, Jie Lu, Shenghua Gao, and Jingyi Yu. 2018. Deep surface light fields. Proceedings of the ACM on Computer Graphics and Interactive Techniques 1, 1 (2018), 1–17.
6. Tianshi Chen, Zidong Du, Ninghui Sun, Jia Wang, Chengyong Wu, Yunji Chen, and Olivier Temam. 2014a. DianNao: A Small-Footprint High-Throughput Accelerator for Ubiquitous Machine-Learning. 42, 1 (feb 2014), 269–284.
7. Yunji Chen, Tao Luo, Shaoli Liu, Shijin Zhang, Liqiang He, Jia Wang, Ling Li, Tianshi Chen, Zhiwei Xu, Ninghui Sun, and Olivier Temam. 2014b. DaDianNao: A Machine-Learning Supercomputer. In 2014 47th Annual IEEE/ACM International Symposium on Microarchitecture. 609–622.
8. Yu-Hsin Chen, Tushar Krishna, Joel S. Emer, and Vivienne Sze. 2017. Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks. IEEE Journal of Solid-State Circuits 52, 1 (jan 2017), 127–138. arXiv:1512.04295
9. Yu-Hsin Chen, Tien-Ju Yang, Joel Emer, and Vivienne Sze. 2019. Eyeriss v2: A Flexible Accelerator for Emerging Deep Neural Networks on Mobile Devices. IEEE Journal on Emerging and Selected Topics in Circuits and Systems 9, 2 (2019), 292–308.
10. Boyang Deng, Jonathan T. Barron, and Pratul P. Srinivasan. 2020. JaxNeRF: an efficient JAX implementation of NeRF. https://github.com/google-research/google-research/tree/master/jaxnerf.
11. Kangle Deng, Andrew Liu, Jun-Yan Zhu, and Deva Ramanan. 2022. Depth-supervised nerf: Fewer views and faster training for free. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12882–12891.
12. Zidong Du, Robert Fasthuber, Tianshi Chen, Paolo Ienne, Ling Li, Tao Luo, Xiaobing Feng, Yunji Chen, and Olivier Temam. 2015. Shi DianNao: Shifting Vision Processing Closer to the Sensor (ISCA ’15). Association for Computing Machinery, New York, NY, USA, 92–104.
13. Brandon Y. Feng and Amitabh Varshney. 2021. SIGNET: Efficient Neural Representations for Light Fields. In International Conference on Computer Vision (ICCV 2021).
14. Stephan J Garbin, Marek Kowalski, Matthew Johnson, Jamie Shotton, and Julien Valentin. 2021. Fastnerf: High-fidelity neural rendering at 200fps. arXiv preprint arXiv:2103.10380 (2021).
15. Dongsoo Han. 2007. Tessellating and Rendering Bezier/B-Spline/NURBS Curves and Surfaces using Geometry Shader in GPU. University of Pennsylvania (2007).
16. Tom’s hardware. 2020. AMD to Introduce New Next-Gen RDNA GPUs in 2020, Not a Typical ‘Refresh’ of Navi. http://https://www.tomshardware.com/news/amds-navi-to-be-refreshed-with-next-gen-rdna-architecture-in-2020
17. Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. 2018. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
18. Jihyuck Jo, Soyoung Cha, Dayoung Rho, and In-Cheol Park. 2018. DSIP: A Scalable Inference Accelerator for Convolutional Neural Networks. IEEE Journal of Solid-State Circuits 53, 2 (2018), 605–618.
19. Norman P. Jouppi, Cliff Young, Nishant Patil, David Patterson, Gaurav Agrawal, Raminder Bajwa, Sarah Bates, Suresh Bhatia, Nan Boden, Al Borchers, Rick Boyle, Pierre-luc Cantin, Clifford Chao, Chris Clark, Jeremy Coriell, Mike Daley, Matt Dau, Jeffrey Dean, Ben Gelb, Tara Vazir Ghaemmaghami, Rajendra Gottipati, William Gulland, Robert Hagmann, C. Richard Ho, Doug Hogberg, John Hu, Robert Hundt, Dan Hurt, Julian Ibarz, Aaron Jaffey, Alek Jaworski, Alexander Kaplan, Harshit Khaitan, Daniel Killebrew, Andy Koch, Naveen Kumar, Steve Lacy, James Laudon, James Law, Diemthu Le, Chris Leary, Zhuyuan Liu, Kyle Lucke, Alan Lundin, Gordon MacKean, Adriana Maggiore, Maire Mahony, Kieran Miller, Rahul Nagarajan, Ravi Narayanaswami, Ray Ni, Kathy Nix, Thomas Norrie, Mark Omernick, Narayana Penukonda, Andy Phelps, Jonathan Ross, Matt Ross, Amir Salek, Emad Samadiani, Chris Severn, Gregory Sizikov, Matthew Snelham, Jed Souter, Dan Steinberg, Andy Swing, Mercedes Tan, Gregory Thorson, Bo Tian, Horia Toma, Erick Tuttle, Vijay Vasudevan, Richard Walter, Walter Wang, Eric Wilcox, and Doe Hyun Yoon. 2017. In-Datacenter Performance Analysis of a Tensor Processing Unit. In Proceedings of the 44th Annual International Symposium on Computer Architecture (Toronto, ON, Canada) (ISCA ’17). Association for Computing Machinery, New York, NY, USA, 1–12.
20. J. T. Kajiya and H. B. Von. 1984. Ray tracing volume densities” computer graphics 18. (1984).
21. Maxim Kazakov. 2007. Catmull-Clark subdivision for geometry shaders. In Proceedings of the 5th international conference on Computer graphics, virtual reality, visualisation and interaction in Africa. 77–84.
22. Hong-Yun Kim, Young-Jun Kim, and Lee-Sup Kim. 2012. MRTP: Mobile Ray Tracing Processor With Reconfigurable Stream Multi-Processors for High Datapath Utilization. IEEE Journal of Solid-State Circuits 47, 2 (2012), 518–535.
23. Hong-Yun Kim, Young-Jun Kim, Jie-Hwan Oh, and Lee-Sup Kim. 2013. A Reconfigurable SIMT Processor for Mobile Ray Tracing With Contention Reduction in Shared Memory. IEEE Transactions on Circuits and Systems I: Regular Papers 60, 4 (2013), 938–950.
24. Daofu Liu, Tianshi Chen, Shaoli Liu, Jinhong Zhou, Shengyuan Zhou, Olivier Teman, Xiaobing Feng, Xuehai Zhou, and Yunji Chen. 2015. PuDianNao: A Polyvalent Machine Learning Accelerator (ASPLOS ’15). Association for Computing Machinery, New York, NY, USA, 369–381.
25. Lingjie Liu, Jiatao Gu, Kyaw Zaw Lin, Tat-Seng Chua, and Christian Theobalt. 2020. Neural sparse voxel fields. arXiv preprint arXiv:2007.11571 (2020).
26. Haimin Luo, Anpei Chen, Qixuan Zhang, Bai Pang, Minye Wu, Lan Xu, and Jingyi Yu. 2021. Convolutional Neural Opacity Radiance Fields. arXiv preprint arXiv:2104.01772 (2021).
27. N. Max. 1995. Optical models for direct volume rendering. IEEE Transactions on Visualization and Computer Graphics 1, 2 (1995), 99–108.
28. Daniel Meister, Shinji Ogaki, Carsten Benthin, Michael J Doyle, Michael Guthe, and Jiří Bittner. 2021. A Survey on Bounding Volume Hierarchies for Ray Tracing. In Computer Graphics Forum, Vol. 40. Wiley Online Library, 683–712.
29. Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. 2020. Nerf: Representing scenes as neural radiance fields for view synthesis. In European conference on computer vision. Springer, 405–421.
30. Bert Moons and Marian Verhelst. 2017. An Energy-Efficient Precision-Scalable ConvNet Processor in 40-nm CMOS. IEEE Journal of Solid-State Circuits 52, 4 (2017), 903–914.
31. Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. 2022. Instant Neural Graphics Primitives with a Multiresolution Hash Encoding. arXiv preprint arXiv:2201.05989 (2022).
32. Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. 2022. Instant Neural Graphics Primitives with a Multiresolution Hash Encoding. ACM Trans. Graph. 41, 4, Article 102 (July 2022), 15 pages.
33. Jae-Ho Nah, Jin-Woo Kim, Junho Park, Won-Jong Lee, Jeong-Soo Park, Seok-Yoon Jung, Woo-Chan Park, Dinesh Manocha, and Tack-Don Han. 2015. HART: A Hybrid Architecture for Ray Tracing Animated Scenes. IEEE Transactions on Visualization and Computer Graphics 21, 3 (2015), 389–401.
34. Jae-Ho Nah, Hyuck-Joo Kwon, Dong-Seok Kim, Cheol-Ho Jeong, Jinhong Park, Tack-Don Han, Dinesh Manocha, and Woo-Chan Park. 2014. RayCore: A Ray-Tracing Hardware Architecture for Mobile Devices. ACM Trans. Graph. 33, 5, Article 162 (sep 2014), 15 pages.
35. Jae-Ho Nah, Jeong-Soo Park, Chanmin Park, Jin-Woo Kim, Yun-Hye Jung, Woo-Chan Park, and Tack-Don Han. 2011. T&I Engine: Traversal and Intersection Engine for Hardware Accelerated Ray Tracing. ACM Trans. Graph. 30, 6 (dec 2011), 1–10.
36. Martin E Newell, RG Newell, and Tom L Sancha. 1972. A solution to the hidden surface problem. In Proceedings of the ACM annual conference-Volume 1. 443–450.
37. Nvidia. 2020. NVIDIA Ampere Architecture. https://www.nvidia.com/en-us/data-center/ampere-architecture/
38. Jongsun Park, Woopyo Jeong, Hamid Mahmoodi-Meimand, Yongtao Wang, Hunsoo Choo, and Kaushik Roy. 2004. Computation sharing programmable FIR filter for low-power and high-performance applications. IEEE Journal of Solid-State Circuits 39, 2 (feb 2004), 348–357.
39. Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Love-grove. 2019. Deepsdf: Learning continuous signed distance functions for shape representation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 165–174.
40. K. Perlin and E. M. Hoffert. 1989. Hypertexture (SIGGRAPH ’89). Association for Computing Machinery, New York, NY, USA, 253–262.
41. Hanspeter Pfister, Jan Hardenbergh, Jim Knittel, Hugh Lauer, and Larry Seiler. 1999. The VolumePro Real-Time Ray-Casting System. In Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques (SIGGRAPH ’99). ACM Press/Addison-Wesley Publishing Co., USA, 251–260.
42. Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred Hamprecht, Yoshua Bengio, and Aaron Courville. 2019. On the spectral bias of neural networks. In International Conference on Machine Learning. PMLR, 5301–5310.
43. Christian Reiser, Songyou Peng, Yiyi Liao, and Andreas Geiger. 2021. KiloNeRF: Speeding up Neural Radiance Fields with Thousands of Tiny MLPs. arXiv preprint arXiv:2103.13744 (2021).
44. VV Sanzharov, Vladimir A Frolov, and Vladimir A Galaktionov. 2020. Survey of Nvidia RTX Technology. Programming and Computer Software 46, 4 (2020), 297–304.
45. Jörg Schmittler, Ingo Wald, and Philipp Slusallek. 2002. SaarCOR: A Hardware Architecture for Ray Tracing. In Proceedings of the ACM SIGGRAPH/EUROGRAPHICS Conference on Graphics Hardware (Saarbrucken, Germany) (HWWS ’02). Eurographics Association, Goslar, DEU, 27–36.
46. Josef Spjut, Andrew Kensler, Daniel Kopta, and Erik Brunvand. 2009. TRaX: A Multicore Hardware Architecture for Real-Time Ray Tracing. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 28, 12 (2009), 1802–1815.
47. Cheng Sun, Min Sun, and Hwann-Tzong Chen. 2021. Direct Voxel Grid Optimization: Super-fast Convergence for Radiance Fields Reconstruction. arXiv preprint arXiv:2111.11215 (2021).
48. Matthew Tancik, Pratul Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan Barron, and Ren Ng. 2020. Fourier features let networks learn high frequency functions in low dimensional domains. Advances in Neural Information Processing Systems 33 (2020).
49. Takashi Totsuka and Marc Levoy. 1993. Frequency domain volume rendering. In Proceedings of the 20th annual conference on Computer graphics and interactive techniques. 271–278.
50. Daniel N Wood, Daniel I Azuma, Ken Aldinger, Brian Curless, Tom Duchamp, David H Salesin, and Werner Stuetzle. 2000. Surface light fields for 3D photography. In Proceedings of the 27th annual conference on Computer graphics and interactive techniques. 287–296.
51. Sven Woop. 2007. A programmable hardware architecture for realtime ray tracing of coherent dynamic scenes. Diss. Ph. D. Thesis, Sarrland University (2007).
52. Sven Woop, Jörg Schmittler, and Philipp Slusallek. 2005. RPU: A Programmable Ray Processing Unit for Realtime Ray Tracing. ACM Trans. Graph. 24, 3 (jul 2005), 434–444.
53. Shouyi Yin, Peng Ouyang, Shibin Tang, Fengbin Tu, Xiudong Li, Shixuan Zheng, Tianyi Lu, Jiangyuan Gu, Leibo Liu, and Shaojun Wei. 2018a. A High Energy Efficient Reconfigurable Hybrid Neural Network Processor for Deep Learning Applications. IEEE Journal of Solid-State Circuits 53, 4 (2018), 968–982.
54. Shouyi Yin, Peng Ouyang, Jianxun Yang, Tianyi Lu, Xiudong Li, Leibo Liu, and Shaojun Wei. 2018b. An Ultra-High Energy-Efficient Reconfigurable Processor for Deep Neural Networks with Binary/Ternary Weights in 28NM CMOS. In 2018 IEEE Symposium on VLSI Circuits. 37–38.
55. Shouyi Yin, Peng Ouyang, Shixuan Zheng, Dandan Song, Xiudong Li, Leibo Liu, and Shaojun Wei. 2018c. A 141 UW, 2.46 PJ/Neuron Binarized Convolutional Neural Network Based Self-Learning Speech Recognition Processor in 28NM CMOS. In 2018 IEEE Symposium on VLSI Circuits. 139–140.
56. Alex Yu, Sara Fridovich-Keil, Matthew Tancik, Qinhong Chen, Benjamin Recht, and Angjoo Kanazawa. 2021a. Plenoxels: Radiance Fields without Neural Networks. arXiv preprint arXiv:2112.05131 (2021).
57. Alex Yu, Ruilong Li, Matthew Tancik, Hao Li, Ren Ng, and Angjoo Kanazawa. 2021b. Plenoctrees for real-time rendering of neural radiance fields. arXiv preprint arXiv:2103.14024 (2021).
58. Huangjie Yu, Anpei Chen, Xin Chen, Lan Xu, Ziyu Shao, and Jingyi Yu. 2022. Anisotropic Fourier Features for Neural Image-Based Rendering and Relighting. In Proceedings of the AAAI Conference on Artificial Intelligence.
59. Ellen D Zhong, Tristan Bepler, Joseph H Davis, and Bonnie Berger. 2019. Reconstructing continuous distributions of 3D protein structure from cryo-EM images. arXiv preprint arXiv:1909.05215 (2019).