
“iNVS: Repurposing Diffusion Inpainters for Novel View Synthesis” by Siarohin, Kant, Vasilkovsky, Guler, Tulyakov, et al. …
Conference:
Type(s):
Title:
- iNVS: Repurposing Diffusion Inpainters for Novel View Synthesis
Session/Category Title:
- View Synthesis
Presenter(s)/Author(s):
Abstract:
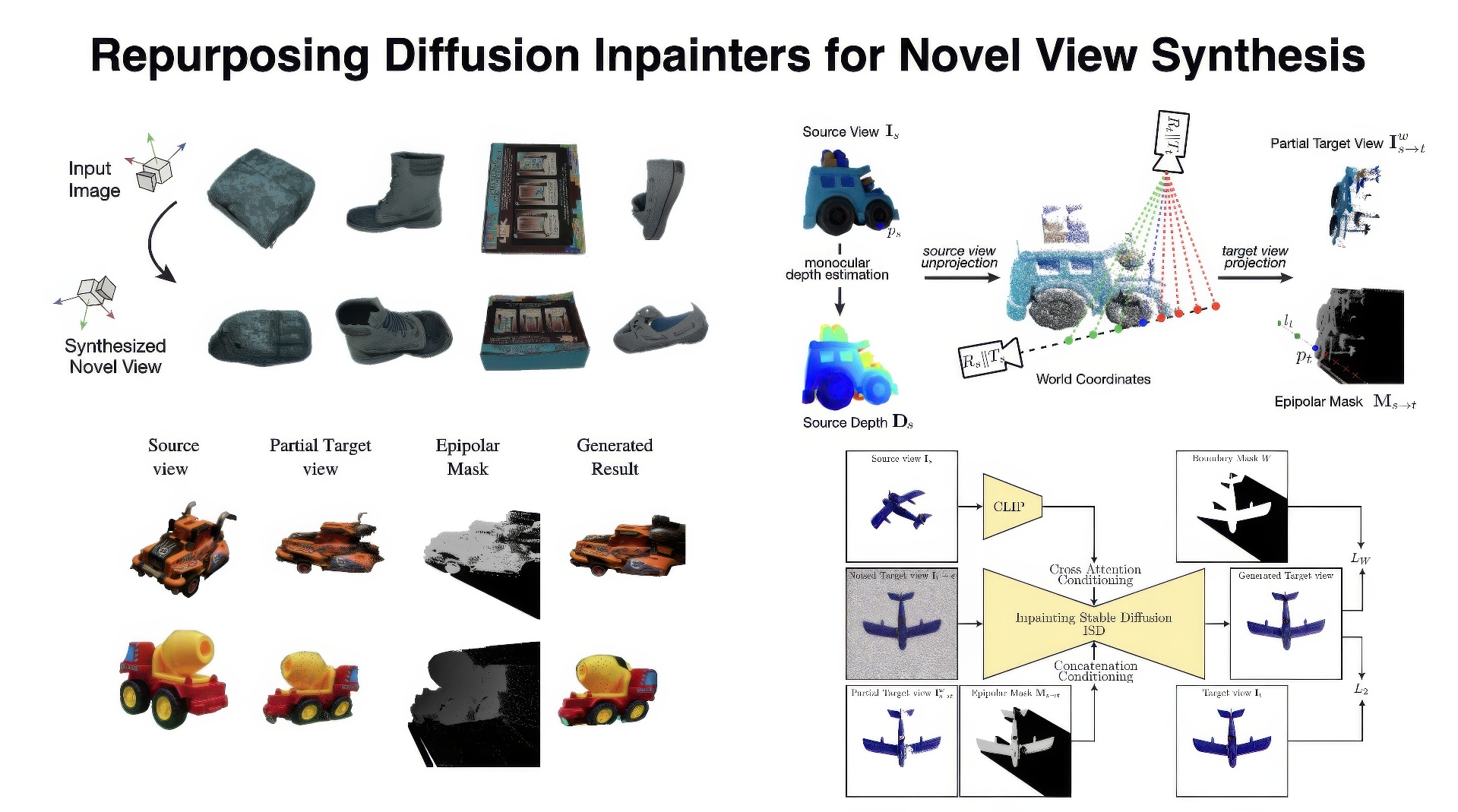
In this paper, we present a method for generating consistent novel views from a single source image. Our approach focuses on maximizing the reuse of visible pixels from the source view. To achieve this, we use a monocular depth estimator that transfers visible pixels from the source view to the target view. Additionally, we leverage a learned object shape prior obtained through 2D inpainting diffusion. We also introduce a dedicated fine-tuning technique using diffusion and a novel masking mechanism based on epipolar lines to further improve the quality of our approach. We train our method on the large-scale Objaverse dataset. This allows our framework to perform zero-shot novel view synthesis on a variety of objects. We evaluate the zero-shot abilities of our framework on three challenging datasets: Google Scanned Objects, Ray Traced Multiview, and Common Objects in 3D.
References:
[1]
Jonathan T Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P Srinivasan. 2021. Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. In Proceedings of the IEEE International Conference on Computer Vision.
[2]
Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter Wonka, and Matthias Müller. 2023. Zoedepth: Zero-shot transfer by combining relative and metric depth. arXiv preprint arXiv:2302.12288 (2023).
[3]
Bharat Lal Bhatnagar, Garvita Tiwari, Christian Theobalt, and Gerard Pons-Moll. 2019. Multi-garment net: Learning to dress 3d people from images. In Proceedings of the IEEE International Conference on Computer Vision.
[4]
Lucy Chai, Richard Tucker, Zhengqi Li, Phillip Isola, and Noah Snavely. 2023. Persistent Nature: A Generative Model of Unbounded 3D Worlds. In CVPR.
[5]
Eric R Chan, Koki Nagano, Matthew A Chan, Alexander W Bergman, Jeong Joon Park, Axel Levy, Miika Aittala, Shalini De Mello, Tero Karras, and Gordon Wetzstein. 2023. Generative novel view synthesis with 3d-aware diffusion models. In Proceedings of the IEEE International Conference on Computer Vision.
[6]
Dave Zhenyu Chen, Yawar Siddiqui, Hsin-Ying Lee, Sergey Tulyakov, and Matthias Nießner. 2023b. Text2Tex: Text-driven Texture Synthesis via Diffusion Models. In Proceedings of the IEEE International Conference on Computer Vision.
[7]
Hao Chen, Bo He, Hanyu Wang, Yixuan Ren, Ser Nam Lim, and Abhinav Shrivastava. 2021. Nerv: Neural representations for videos. Advances in Neural Information Processing Systems (2021).
[8]
Rui Chen, Yongwei Chen, Ningxin Jiao, and Kui Jia. 2023a. Fantasia3D: Disentangling Geometry and Appearance for High-quality Text-to-3D Content Creation. In Proceedings of the IEEE International Conference on Computer Vision.
[9]
Shenchang Eric Chen and Lance Williams. 1993. View Interpolation for Image Synthesis. In Special Interest Group on Computer Graphics and Interactive Techniques.
[10]
Inchang Choi, Orazio Gallo, Alejandro Troccoli, Min H Kim, and Jan Kautz. 2019. Extreme view synthesis. In Proceedings of the IEEE International Conference on Computer Vision.
[11]
Paul E. Debevec, Camillo J. Taylor, and Jitendra Malik. 1996. Modeling and Rendering Architecture from Photographs: A Hybrid Geometry- and Image-Based Approach. In Special Interest Group on Computer Graphics and Interactive Techniques.
[12]
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. 2023. Objaverse: A universe of annotated 3d objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
[13]
Kangle Deng, Gengshan Yang, Deva Ramanan, and Jun-Yan Zhu. 2023. 3d-aware conditional image synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
[14]
Emily Denton and Rob Fergus. 2018. Stochastic video generation with a learned prior. In Proceedings of the International Conference on Machine Learning.
[15]
Prafulla Dhariwal and Alexander Nichol. 2021. Diffusion models beat gans on image synthesis. Advances in Neural Information Processing Systems (2021).
[16]
Laura Downs, Anthony Francis, Nate Koenig, Brandon Kinman, Ryan Hickman, Krista Reymann, Thomas B McHugh, and Vincent Vanhoucke. 2022. Google scanned objects: A high-quality dataset of 3d scanned household items. In Proceedings of the IEEE International Conference on Robotics and Automation.
[17]
Chelsea Finn, Ian Goodfellow, and Sergey Levine. 2016. Unsupervised learning for physical interaction through video prediction. Advances in Neural Information Processing Systems (2016).
[18]
Chen Gao, Ayush Saraf, Johannes Kopf, and Jia-Bin Huang. 2021. Dynamic view synthesis from dynamic monocular video. In Proceedings of the IEEE International Conference on Computer Vision.
[19]
Jiatao Gu, Alex Trevithick, Kai-En Lin, Joshua M Susskind, Christian Theobalt, Lingjie Liu, and Ravi Ramamoorthi. 2023. Nerfdiff: Single-image view synthesis with nerf-guided distillation from 3d-aware diffusion. In Proceedings of the International Conference on Machine Learning.
[20]
Jun-Ting Hsieh, Bingbin Liu, De-An Huang, Li F Fei-Fei, and Juan Carlos Niebles. 2018. Learning to decompose and disentangle representations for video prediction. Advances in Neural Information Processing Systems (2018).
[21]
Pengpeng Hu, Edmond Shu-Lim Ho, and Adrian Munteanu. 2021a. 3DBodyNet: fast reconstruction of 3D animatable human body shape from a single commodity depth camera. IEEE Transactions on Multimedia (2021).
[22]
Ronghang Hu, Nikhila Ravi, Alexander C Berg, and Deepak Pathak. 2021b. Worldsheet: Wrapping the world in a 3d sheet for view synthesis from a single image. In Proceedings of the IEEE International Conference on Computer Vision.
[23]
Luo Jiang, Juyong Zhang, Bailin Deng, Hao Li, and Ligang Liu. 2018. 3D face reconstruction with geometry details from a single image. IEEE Transactions on Image Processing (2018).
[24]
Heewoo Jun and Alex Nichol. 2023. Shap-e: Generating conditional 3d implicit functions. arXiv preprint arXiv:2305.02463 (2023).
[25]
Ira Kemelmacher-Shlizerman and Ronen Basri. 2010. 3D face reconstruction from a single image using a single reference face shape. IEEE Transactions on Pattern Analysis and Machine Intelligence (2010).
[26]
Jing Yu Koh, Honglak Lee, Yinfei Yang, Jason Baldridge, and Peter Anderson. 2021. Pathdreamer: A world model for indoor navigation. ICCV.
[27]
Zhengfei Kuang, Kyle Olszewski, Menglei Chai, Zeng Huang, Panos Achlioptas, and Sergey Tulyakov. 2022. NeROIC: Neural Rendering of Objects from Online Image Collections. In Special Interest Group on Computer Graphics and Interactive Techniques.
[28]
Lambda Labs. 2023. Stable Diffusion Image Variations. https://huggingface.co/spaces/lambdalabs/stable-diffusion-image-variations. Accessed on 2023-05-22.
[29]
Wonkwang Lee, Whie Jung, Han Zhang, Ting Chen, Jing Yu Koh, Thomas Huang, Hyungsuk Yoon, Honglak Lee, and Seunghoon Hong. 2021. Revisiting hierarchical approach for persistent long-term video prediction. In Proceedings of the International Conference on Learning Representations.
[30]
Zhengqi Li, Richard Tucker, Noah Snavely, and Aleksander Holynski. 2023. Generative Image Dynamics. arXiv preprint arXiv:2309.07906 (2023).
[31]
Zhengqi Li, Qianqian Wang, Noah Snavely, and Angjoo Kanazawa. 2022a. Infinitenature-zero: Learning perpetual view generation of natural scenes from single images. In Proceedings of the European Conference on Computer Vision.
[32]
Zhengqi Li, Qianqian Wang, Noah Snavely, and Angjoo Kanazawa. 2022b. Infinitenature-zero: Learning perpetual view generation of natural scenes from single images. In Proceedings of the European Conference on Computer Vision.
[33]
Tingting Liao, Xiaomei Zhang, Yuliang Xiu, Hongwei Yi, Xudong Liu, Guo-Jun Qi, Yong Zhang, Xuan Wang, Xiangyu Zhu, and Zhen Lei. 2023. High-Fidelity Clothed Avatar Reconstruction from a Single Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
[34]
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. 2023. Magic3d: High-resolution text-to-3d content creation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
[35]
Andrew Liu, Richard Tucker, Varun Jampani, Ameesh Makadia, Noah Snavely, and Angjoo Kanazawa. 2021. Infinite Nature: Perpetual View Generation of Natural Scenes from a Single Image. In Proceedings of the IEEE International Conference on Computer Vision.
[36]
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl Vondrick. 2023. Zero-1-to-3: Zero-shot One Image to 3D Object. In Proceedings of the IEEE International Conference on Computer Vision.
[37]
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. 2022. Repaint: Inpainting using denoising diffusion probabilistic models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
[38]
Aniruddha Mahapatra and Kuldeep Kulkarni. 2022. Controllable Animation of Fluid Elements in Still Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3667–3676.
[39]
Ricardo Martin-Brualla, Noha Radwan, Mehdi SM Sajjadi, Jonathan T Barron, Alexey Dosovitskiy, and Daniel Duckworth. 2021. Nerf in the wild: Neural radiance fields for unconstrained photo collections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
[40]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. 2020. Nerf: Representing scenes as neural radiance fields for view synthesis. In Proceedings of the European Conference on Computer Vision.
[41]
Ashkan Mirzaei, Tristan Aumentado-Armstrong, Marcus A Brubaker, Jonathan Kelly, Alex Levinshtein, Konstantinos G Derpanis, and Igor Gilitschenski. 2023. Reference-guided Controllable Inpainting of Neural Radiance Fields. In Proceedings of the IEEE International Conference on Computer Vision.
[42]
Alex Nichol, Heewoo Jun, Prafulla Dhariwal, Pamela Mishkin, and Mark Chen. 2022. Point-e: A system for generating 3d point clouds from complex prompts. arXiv preprint arXiv:2212.08751 (2022).
[43]
Simon Niklaus and Feng Liu. 2020. Softmax splatting for video frame interpolation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
[44]
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. 2023. DreamFusion: Text-to-3D using 2D Diffusion. In Proceedings of the International Conference on Learning Representations.
[45]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, 2021. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning.
[46]
Amit Raj, Srinivas Kaza, Ben Poole, Michael Niemeyer, Nataniel Ruiz, Ben Mildenhall, Shiran Zada, Kfir Aberman, Michael Rubinstein, Jonathan Barron, 2023. DreamBooth3D: Subject-Driven Text-to-3D Generation. arXiv preprint arXiv:2303.13508 (2023).
[47]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. 2022. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 (2022).
[48]
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. 2021. Zero-shot text-to-image generation. In Proceedings of the International Conference on Machine Learning.
[49]
Jeremy Reizenstein, Roman Shapovalov, Philipp Henzler, Luca Sbordone, Patrick Labatut, and David Novotny. 2021. Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. In Proceedings of the IEEE International Conference on Computer Vision.
[50]
Elad Richardson, Gal Metzer, Yuval Alaluf, Raja Giryes, and Daniel Cohen-Or. 2023. TEXTure: Text-Guided Texturing of 3D Shapes. In Special Interest Group on Computer Graphics and Interactive Techniques.
[51]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
[52]
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. 2015. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer Assisted Intervention.
[53]
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. 2023. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
[54]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, 2022. Photorealistic text-to-image diffusion models with deep language understanding. Advances in Neural Information Processing Systems (2022).
[55]
Mehdi SM Sajjadi, Henning Meyer, Etienne Pot, Urs Bergmann, Klaus Greff, Noha Radwan, Suhani Vora, Mario Lučić, Daniel Duckworth, Alexey Dosovitskiy, 2022. Scene representation transformer: Geometry-free novel view synthesis through set-latent scene representations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
[56]
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, 2022. Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in Neural Information Processing Systems (2022).
[57]
Qiuhong Shen, Xingyi Yang, and Xinchao Wang. 2023. Anything-3d: Towards single-view anything reconstruction in the wild. arXiv preprint arXiv:2304.10261 (2023).
[58]
Meng-Li Shih, Shih-Yang Su, Johannes Kopf, and Jia-Bin Huang. 2020. 3D Photography using Context-aware Layered Depth Inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
[59]
Aliaksandr Siarohin, Stéphane Lathuilière, Sergey Tulyakov, Elisa Ricci, and Nicu Sebe. 2019a. First order motion model for image animation. Advances in Neural Information Processing Systems (2019).
[60]
Aliaksandr Siarohin, Stéphane Lathuilière, Sergey Tulyakov, Elisa Ricci, and Nicu Sebe. 2019b. Animating Arbitrary Objects via Deep Motion Transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
[61]
Junshu Tang, Tengfei Wang, Bo Zhang, Ting Zhang, Ran Yi, Lizhuang Ma, and Dong Chen. 2023. Make-it-3d: High-fidelity 3d creation from a single image with diffusion prior. Proceedings of the IEEE International Conference on Computer Vision.
[62]
Jonathan Tremblay, Moustafa Meshry, Alex Evans, Jan Kautz, Alexander Keller, Sameh Khamis, Charles Loop, Nathan Morrical, Koki Nagano, Towaki Takikawa, and Stan Birchfield. 2022. RTMV: A Ray-Traced Multi-View Synthetic Dataset for Novel View Synthesis. Proceedings of the European Conference on Computer Vision Workshop (2022).
[63]
Richard Tucker and Noah Snavely. 2020. Single-view view synthesis with multiplane images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
[64]
Ruben Villegas, Jimei Yang, Seunghoon Hong, Xunyu Lin, and Honglak Lee. 2017. Decomposing motion and content for natural video sequence prediction. In Proceedings of the International Conference on Learning Representations.
[65]
Carl Vondrick and Antonio Torralba. 2017. Generating the Future With Adversarial Transformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
[66]
Yunbo Wang, Mingsheng Long, Jianmin Wang, Zhifeng Gao, and Philip S Yu. 2017. PredRNN: Recurrent Neural Networks for Predictive Learning Using Spatiotemporal LSTMs. Advances in Neural Information Processing Systems (2017).
[67]
Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli. 2004. Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing (2004).
[68]
Zirui Wang, Shangzhe Wu, Weidi Xie, Min Chen, and Victor Adrian Prisacariu. 2021. NeRF − −: Neural Radiance Fields Without Known Camera Parameters. arXiv preprint arXiv:2102.07064 (2021).
[69]
Daniel Watson, William Chan, Ricardo Martin Brualla, Jonathan Ho, Andrea Tagliasacchi, and Mohammad Norouzi. 2022. Novel View Synthesis with Diffusion Models. In Proceedings of the International Conference on Learning Representations.
[70]
Olivia Wiles, Georgia Gkioxari, Richard Szeliski, and Justin Johnson. 2020. Synsin: End-to-end view synthesis from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
[71]
Yuliang Xiu, Jinlong Yang, Xu Cao, Dimitrios Tzionas, and Michael J. Black. 2023. ECON: Explicit Clothed humans Optimized via Normal integration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
[72]
Yufei Ye, Maneesh Singh, Abhinav Gupta, and Shubham Tulsiani. 2019. Compositional video prediction. In Proceedings of the IEEE International Conference on Computer Vision.
[73]
Sihyun Yu, Jihoon Tack, Sangwoo Mo, Hyunsu Kim, Junho Kim, Jung-Woo Ha, and Jinwoo Shin. 2022. Generating videos with dynamics-aware implicit generative adversarial networks. In Proceedings of the International Conference on Learning Representations.
[74]
Kai Zhang, Gernot Riegler, Noah Snavely, and Vladlen Koltun. 2020. Nerf++: Analyzing and improving neural radiance fields. arXiv preprint arXiv:2010.07492 (2020).
[75]
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. 2018. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
[76]
Zhizhuo Zhou and Shubham Tulsiani. 2023. SparseFusion: Distilling View-conditioned Diffusion for 3D Reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.