
“SinMPI: Novel View Synthesis from a Single Image with Expanded Multiplane Images” by Pu, Wang and Lian
Conference:
Type(s):
Title:
- SinMPI: Novel View Synthesis from a Single Image with Expanded Multiplane Images
Session/Category Title:
- View Synthesis
Presenter(s)/Author(s):
Abstract:
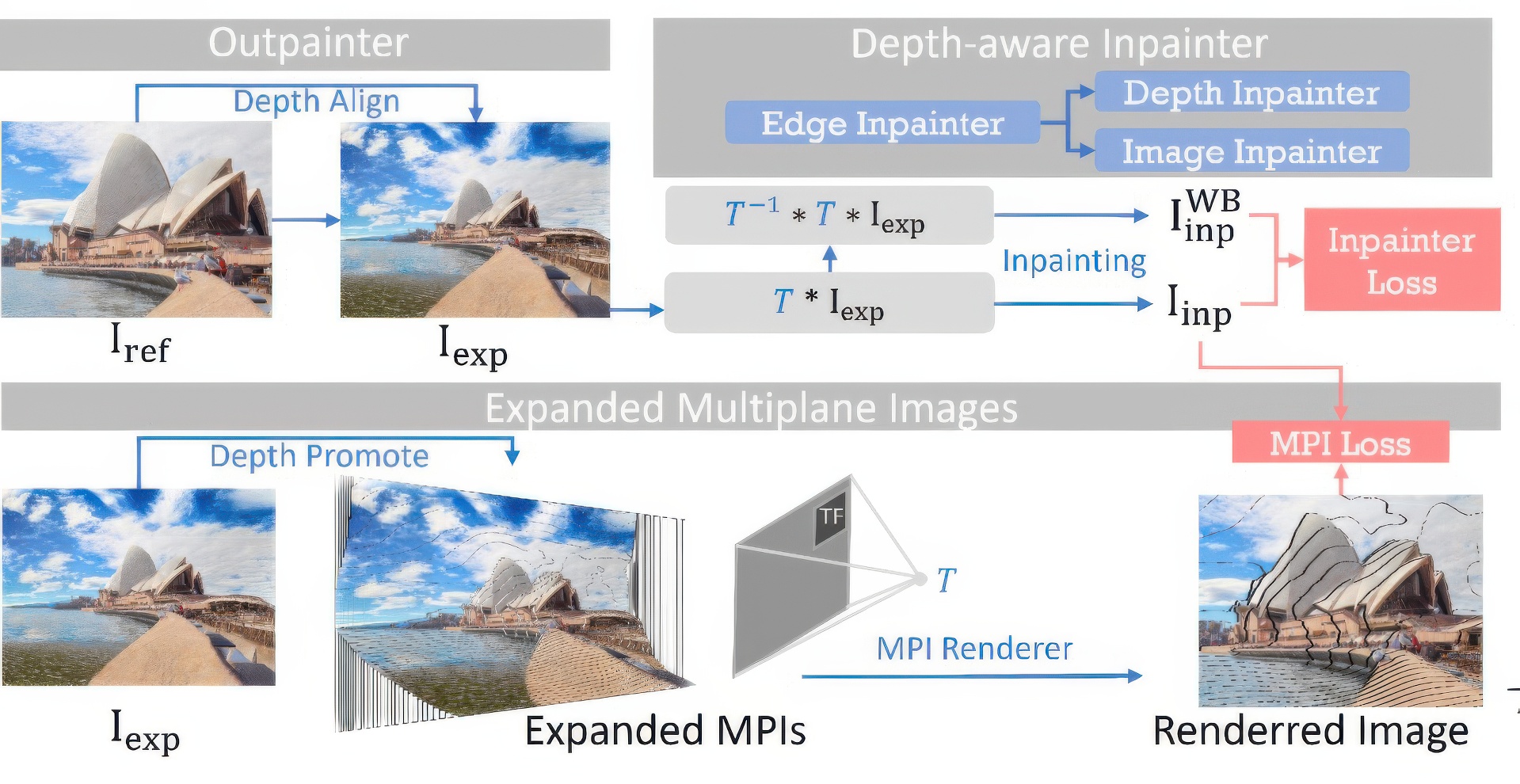
Single-image novel view synthesis is a challenging and ongoing problem that aims to generate an infinite number of consistent views from a single input image. Although significant efforts have been made to advance the quality of generated novel views, less attention has been paid to the expansion of the underlying scene representation, which is crucial to the generation of realistic novel view images. This paper proposes SinMPI, a novel method that uses expanded multiplane images (MPIs) as the 3D scene representation to significantly expand the perspective range of MPIs and generate high-quality novel views from a large multiplane space. The key idea of our method is to use Stable Diffusion~\cite{rombach2021highresolution} to generate out-of-view contents, project all scene contents into expanded multiplane images, and then optimize the multiplane images under the supervision of pseudo-multi-view data generated by a depth-aware warping and inpainting module. Both qualitative and quantitative experiments have been conducted to validate the superiority of our method to the state of the art. Our code and data are available at https://github.com/TrickyGo/SinMPI.
References:
[1]
Holger Caesar, Jasper Uijlings, and Vittorio Ferrari. 2018. Coco-stuff: Thing and stuff classes in context. In Proceedings of the IEEE conference on computer vision and pattern recognition. 1209–1218.
[2]
Shengqu Cai, Anton Obukhov, Dengxin Dai, and Luc Van Gool. 2022. Pix2NeRF: Unsupervised Conditional p-GAN for Single Image to Neural Radiance Fields Translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3981–3990.
[3]
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. 2021. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision. 9650–9660.
[4]
Congyue Deng, Chiyu Jiang, Charles R Qi, Xinchen Yan, Yin Zhou, Leonidas Guibas, Dragomir Anguelov, 2023. Nerdi: Single-view nerf synthesis with language-guided diffusion as general image priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 20637–20647.
[5]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition. Ieee, 248–255.
[6]
Kangle Deng, Andrew Liu, Jun-Yan Zhu, and Deva Ramanan. 2022. Depth-supervised nerf: Fewer views and faster training for free. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12882–12891.
[7]
John Flynn, Michael Broxton, Paul Debevec, Matthew DuVall, Graham Fyffe, Ryan Overbeck, Noah Snavely, and Richard Tucker. 2019. Deepview: View synthesis with learned gradient descent. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2367–2376.
[8]
Chen Gao, Yichang Shih, Wei-Sheng Lai, Chia-Kai Liang, and Jia-Bin Huang. 2020. Portrait neural radiance fields from a single image. arXiv preprint arXiv:2012.05903 (2020).
[9]
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2020. Generative adversarial networks. Commun. ACM 63, 11 (2020), 139–144.
[10]
Jiatao Gu, Alex Trevithick, Kai-En Lin, Joshua M Susskind, Christian Theobalt, Lingjie Liu, and Ravi Ramamoorthi. 2023. Nerfdiff: Single-image view synthesis with nerf-guided distillation from 3d-aware diffusion. In International Conference on Machine Learning. PMLR, 11808–11826.
[11]
Yuxuan Han, Ruicheng Wang, and Jiaolong Yang. 2022. Single-View View Synthesis in the Wild with Learned Adaptive Multiplane Images. arXiv preprint arXiv:2205.11733 (2022).
[12]
Richard Hartley and Andrew Zisserman. 2003. Multiple view geometry in computer vision. Cambridge university press.
[13]
Baichuan Huang, Hongwei Yi, Can Huang, Yijia He, Jingbin Liu, and Xiao Liu. 2021. M3VSNet: Unsupervised multi-metric multi-view stereo network. In 2021 IEEE International Conference on Image Processing (ICIP). IEEE, 3163–3167.
[14]
Ajay Jain, Matthew Tancik, and Pieter Abbeel. 2021. Putting nerf on a diet: Semantically consistent few-shot view synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 5885–5894.
[15]
Varun Jampani, Huiwen Chang, Kyle Sargent, Abhishek Kar, Richard Tucker, Michael Krainin, Dominik Kaeser, William T Freeman, David Salesin, Brian Curless, 2021. SLIDE: Single image 3d photography with soft layering and depth-aware inpainting. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 12518–12527.
[16]
Rasmus Jensen, Anders Dahl, George Vogiatzis, Engin Tola, and Henrik Aanæs. 2014. Large scale multi-view stereopsis evaluation. In Proceedings of the IEEE conference on computer vision and pattern recognition. 406–413.
[17]
Jiaxin Li, Zijian Feng, Qi She, Henghui Ding, Changhu Wang, and Gim Hee Lee. 2021. Mine: Towards continuous depth mpi with nerf for novel view synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 12578–12588.
[18]
Qinbo Li and Nima Khademi Kalantari. 2020. Synthesizing light field from a single image with variable MPI and two network fusion.ACM Trans. Graph. 39, 6 (2020), 229–1.
[19]
Zhengqi Li, Qianqian Wang, Noah Snavely, and Angjoo Kanazawa. 2022. InfiniteNature-Zero: Learning Perpetual View Generation of Natural Scenes from Single Images. In European Conference on Computer Vision. Springer, 515–534.
[20]
Kai-En Lin, Yen-Chen Lin, Wei-Sheng Lai, Tsung-Yi Lin, Yi-Chang Shih, and Ravi Ramamoorthi. 2023. Vision transformer for nerf-based view synthesis from a single input image. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 806–815.
[21]
Andrew Liu, Richard Tucker, Varun Jampani, Ameesh Makadia, Noah Snavely, and Angjoo Kanazawa. 2021. Infinite nature: Perpetual view generation of natural scenes from a single image. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 14458–14467.
[22]
Ben Mildenhall, Pratul P Srinivasan, Rodrigo Ortiz-Cayon, Nima Khademi Kalantari, Ravi Ramamoorthi, Ren Ng, and Abhishek Kar. 2019. Local light field fusion: Practical view synthesis with prescriptive sampling guidelines. ACM Transactions on Graphics (TOG) 38, 4 (2019), 1–14.
[23]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. 2021. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 65, 1 (2021), 99–106.
[24]
Kamyar Nazeri, Eric Ng, Tony Joseph, Faisal Qureshi, and Mehran Ebrahimi. 2019. Edgeconnect: Structure guided image inpainting using edge prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops. 0–0.
[25]
Martin E Newell, RG Newell, and Tom L Sancha. 1972. A solution to the hidden surface problem. In Proceedings of the ACM annual conference-Volume 1. 443–450.
[26]
René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. 2021. Vision transformers for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 12179–12188.
[27]
Chris Rockwell, David F Fouhey, and Justin Johnson. 2021. Pixelsynth: Generating a 3d-consistent experience from a single image. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 14104–14113.
[28]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2021. High-Resolution Image Synthesis with Latent Diffusion Models. arxiv:2112.10752 [cs.CV]
[29]
Jonathan Shade, Steven Gortler, Li-wei He, and Richard Szeliski. 1998. Layered depth images. In Proceedings of the 25th annual conference on Computer graphics and interactive techniques. 231–242.
[30]
Meng-Li Shih, Shih-Yang Su, Johannes Kopf, and Jia-Bin Huang. 2020. 3d photography using context-aware layered depth inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8028–8038.
[31]
Pratul P Srinivasan, Richard Tucker, Jonathan T Barron, Ravi Ramamoorthi, Ren Ng, and Noah Snavely. 2019. Pushing the boundaries of view extrapolation with multiplane images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 175–184.
[32]
Pratul P Srinivasan, Tongzhou Wang, Ashwin Sreelal, Ravi Ramamoorthi, and Ren Ng. 2017. Learning to synthesize a 4D RGBD light field from a single image. In Proceedings of the IEEE International Conference on Computer Vision. 2243–2251.
[33]
Richard Szeliski and Polina Golland. 1999. Stereo matching with transparency and matting. International Journal of Computer Vision 32, 1 (1999), 45–61.
[34]
Carlo Tomasi and Roberto Manduchi. 1998. Bilateral filtering for gray and color images. In Sixth international conference on computer vision (IEEE Cat. No. 98CH36271). IEEE, 839–846.
[35]
Richard Tucker and Noah Snavely. 2020. Single-view view synthesis with multiplane images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 551–560.
[36]
Daniel Watson, William Chan, Ricardo Martin-Brualla, Jonathan Ho, Andrea Tagliasacchi, and Mohammad Norouzi. 2022. Novel view synthesis with diffusion models. arXiv preprint arXiv:2210.04628 (2022).
[37]
Olivia Wiles, Georgia Gkioxari, Richard Szeliski, and Justin Johnson. 2020. Synsin: End-to-end view synthesis from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7467–7477.
[38]
Suttisak Wizadwongsa, Pakkapon Phongthawee, Jiraphon Yenphraphai, and Supasorn Suwajanakorn. 2021. Nex: Real-time view synthesis with neural basis expansion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8534–8543.
[39]
Dejia Xu, Yifan Jiang, Peihao Wang, Zhiwen Fan, Humphrey Shi, and Zhangyang Wang. 2022. SinNeRF: Training Neural Radiance Fields on Complex Scenes from a Single Image. arXiv preprint arXiv:2204.00928 (2022).
[40]
Qiangeng Xu, Weiyue Wang, Duygu Ceylan, Radomir Mech, and Ulrich Neumann. 2019. Disn: Deep implicit surface network for high-quality single-view 3d reconstruction. Advances in Neural Information Processing Systems 32 (2019).
[41]
Wei Yin, Jianming Zhang, Oliver Wang, Simon Niklaus, Long Mai, Simon Chen, and Chunhua Shen. 2021. Learning to recover 3d scene shape from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 204–213.
[42]
Alex Yu, Vickie Ye, Matthew Tancik, and Angjoo Kanazawa. 2021. pixelnerf: Neural radiance fields from one or few images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4578–4587.
[43]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. 2018. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition. 586–595.
[44]
Xiaoming Zhao, Fangchang Ma, David Güera, Zhile Ren, Alexander G Schwing, and Alex Colburn. 2022. Generative multiplane images: Making a 2d gan 3d-aware. In European Conference on Computer Vision. Springer, 18–35.
[45]
Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. 2017a. Places: A 10 million image database for scene recognition. IEEE transactions on pattern analysis and machine intelligence 40, 6 (2017), 1452–1464.
[46]
Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. 2017b. Scene parsing through ade20k dataset. In Proceedings of the IEEE conference on computer vision and pattern recognition. 633–641.
[47]
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. 2018. Stereo magnification: Learning view synthesis using multiplane images. arXiv preprint arXiv:1805.09817 (2018).