
“Layered neural atlases for consistent video editing” by Kasten, Ofri, Wang and Dekel
Conference:
Type(s):
Title:
- Layered neural atlases for consistent video editing
Session/Category Title:
- Computational Photography
Presenter(s)/Author(s):
Abstract:
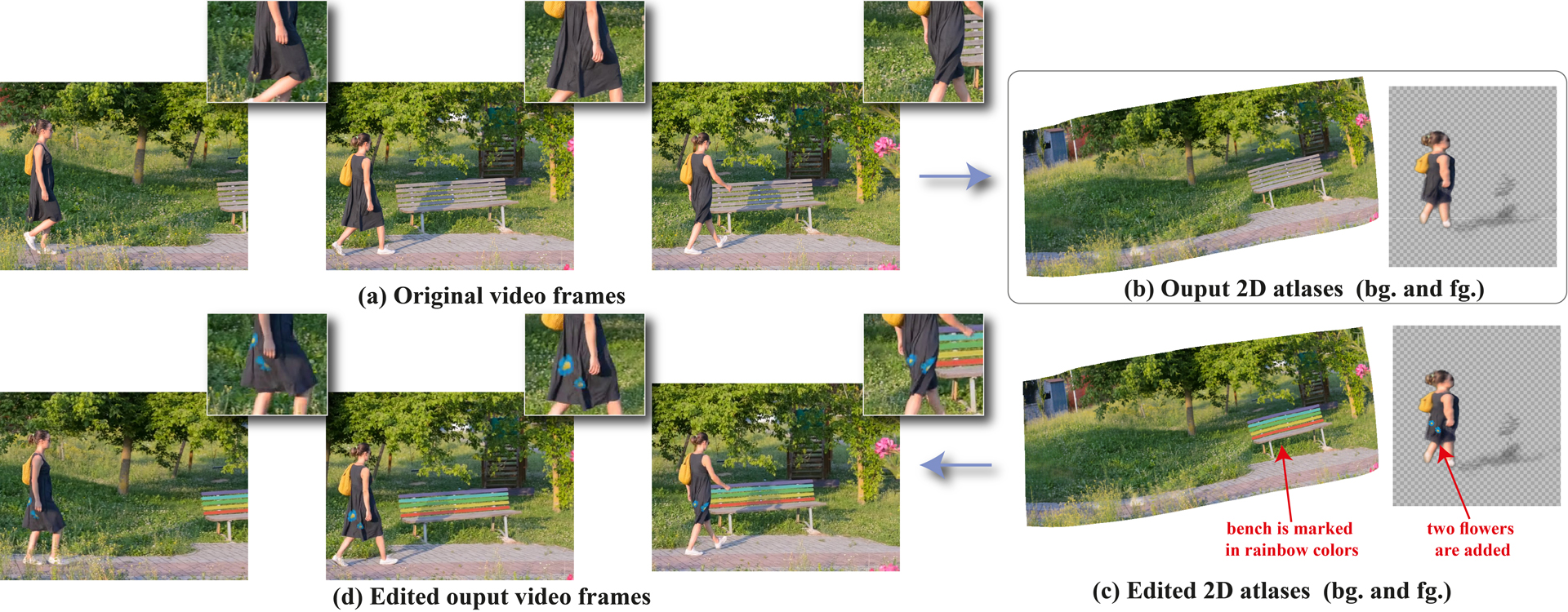
We present a method that decomposes, and “unwraps”, an input video into a set of layered 2D atlases, each providing a unified representation of the appearance of an object (or background) over the video. For each pixel in the video, our method estimates its corresponding 2D coordinate in each of the atlases, giving us a consistent parameterization of the video, along with an associated alpha (opacity) value. Importantly, we design our atlases to be interpretable and semantic, which facilitates easy and intuitive editing in the atlas domain, with minimal manual work required. Edits applied to a single 2D atlas (or input video frame) are automatically and consistently mapped back to the original video frames, while preserving occlusions, deformation, and other complex scene effects such as shadows and reflections. Our method employs a coordinate-based Multilayer Perceptron (MLP) representation for mappings, atlases, and alphas, which are jointly optimized on a per-video basis, using a combination of video reconstruction and regularization losses. By operating purely in 2D, our method does not require any prior 3D knowledge about scene geometry or camera poses, and can handle complex dynamic real world videos. We demonstrate various video editing applications, including texture mapping, video style transfer, image-to-video texture transfer, and segmentation/labeling propagation, all automatically produced by editing a single 2D atlas image.
References:
1. Adobe. 2021. Adobe After Effects CC. https://www.adobe.com/products/aftereffects.html
2. Aseem Agarwala, Ke Colin Zheng, Chris Pal, Maneesh Agrawala, Michael Cohen, Brian Curless, David Salesin, and Richard Szeliski. 2005. Panoramic video textures. In ACM SIGGRAPH 2005 Papers. 821–827.
3. Sanjeev Arora, Simon Du, Wei Hu, Zhiyuan Li, and Ruosong Wang. 2019. Fine-grained analysis of optimization and generalization for overparameterized two-layer neural networks. In International Conference on Machine Learning. PMLR, 322–332.
4. Connelly Barnes, Dan B Goldman, Eli Shechtman, and Adam Finkelstein. 2010. Video tapestries with continuous temporal zoom. In ACM SIGGRAPH 2010 papers. 1–9.
5. Matthew Brown and David G Lowe. 2007. Automatic panoramic image stitching using invariant features. International journal of computer vision 74, 1 (2007), 59–73.
6. Yinbo Chen, Sifei Liu, and Xiaolong Wang. 2020. Learning Continuous Image Representation with Local Implicit Image Function. arXiv preprint arXiv:2012.09161 (2020).
7. Carlos D Correa and Kwan-Liu Ma. 2010. Dynamic video narratives. In ACM SIGGRAPH 2010 papers. 1–9.
8. Thibault Groueix, Matthew Fisher, Vladimir G Kim, Bryan C Russell, and Mathieu Aubry. 2018. A papier-mâché approach to learning 3d surface generation. In Proceedings of the IEEE conference on computer vision and pattern recognition. 216–224.
9. Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. 2017. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision. 2961–2969.
10. Michal Irani and Prabu Anandan. 1998. Video indexing based on mosaic representations. Proc. IEEE 86, 5 (1998), 905–921.
11. Michal Irani, P Anandan, and Steve Hsu. 1995. Mosaic based representations of video sequences and their applications. In Proceedings of IEEE International Conference on Computer Vision. IEEE, 605–611.
12. Allan Jabri, Andrew Owens, and Alexei A Efros. 2020. Space-time correspondence as a contrastive random walk. arXiv preprint arXiv:2006.14613 (2020).
13. Varun Jampani, Raghudeep Gadde, and Peter V Gehler. 2017. Video propagation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 451–461.
14. Nicholas Kolkin, Jason Salavon, and Gregory Shakhnarovich. 2019. Style transfer by relaxed optimal transport and self-similarity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10051–10060.
15. Zhengqi Li, Simon Niklaus, Noah Snavely, and Oliver Wang. 2020. Neural Scene Flow Fields for Space-Time View Synthesis of Dynamic Scenes. arXiv preprint arXiv:2011.13084 (2020).
16. Sharon Lin, Matthew Fisher, Angela Dai, and Pat Hanrahan. 2017. LayerBuilder: Layer decomposition for interactive image and video color editing. arXiv preprint arXiv:1701.03754 (2017).
17. E Lu,, F Cole, T Dekel, A Zisserman, WT Freeman, and M Rubinstein. 2021. Omnimatte: associating objects and their effects in video. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR).
18. Erika Lu, Forrester Cole, Tali Dekel, Weidi Xie, Andrew Zisserman, David Salesin, William T. Freeman, and Michael Rubinstein. 2020. Layered neural rendering for retiming people in video. ACM Trans. Graph. 39, 6 (2020), 256:1–256:14.
19. Xuan Luo, Jia-Bin Huang, Richard Szeliski, Kevin Matzen, and Johannes Kopf. 2020. Consistent video depth estimation. ACM Transactions on Graphics (TOG) 39, 4 (2020), 71–1.
20. Lars Mescheder, Michael Oechsle, Michael Niemeyer, Sebastian Nowozin, and Andreas Geiger. 2019. Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4460–4470.
21. Simone Meyer, Alexander Sorkine-Hornung, and Markus Gross. 2016. Phase-based modification transfer for video. In European Conference on Computer Vision. Springer, 633–648.
22. Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. 2020. Nerf: Representing scenes as neural radiance fields for view synthesis. In European Conference on Computer Vision. Springer, 405–421.
23. Seoung Wug Oh, Joon-Young Lee, Kalyan Sunkavalli, and Seon Joo Kim. 2018. Fast video object segmentation by reference-guided mask propagation. In Proceedings of the IEEE conference on computer vision and pattern recognition. 7376–7385.
24. Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Lovegrove. 2019. DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
25. Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Arbeláez, Alexander Sorkine-Hornung, and Luc Van Gool. 2017. The 2017 DAVIS Challenge on Video Object Segmentation. arXiv:1704.00675 (2017).
26. Michael Rabinovich, Roi Poranne, Daniele Panozzo, and Olga Sorkine-Hornung. 2017. Scalable locally injective mappings. ACM Transactions on Graphics (TOG) 36, 4 (2017), 1.
27. Alex Rav-Acha, Pushmeet Kohli, Carsten Rother, and Andrew Fitzgibbon. 2008. Unwrap mosaics: A new representation for video editing. In ACM SIGGRAPH 2008 papers. 1–11.
28. Roger Blanco I Ribera, Sungwoo Choi, Younghui Kim, JungJin Lee, and Junyong Noh. 2012. Video panorama for 2d to 3d conversion. In Computer Graphics Forum, Vol. 31. Wiley Online Library, 2213–2222.
29. Lars Schnyder, Oliver Wang, and Aljoscha Smolic. 2011. 2D to 3D conversion of sports content using panoramas. In 2011 18th IEEE International Conference on Image Processing. IEEE, 1961–1964.
30. Jonathan Shade, Steven Gortler, Li-wei He, and Richard Szeliski. 1998. Layered depth images. In Proceedings of the 25th annual conference on Computer graphics and interactive techniques. 231–242.
31. Vincent Sitzmann, Julien Martel, Alexander Bergman, David Lindell, and Gordon Wetzstein. 2020. Implicit neural representations with periodic activation functions. Advances in Neural Information Processing Systems 33 (2020).
32. Matthew Tancik, Pratul P. Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T. Barron, and Ren Ng. 2020. Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains. NeurIPS (2020).
33. Zachary Teed and Jia Deng. 2020. Raft: Recurrent all-pairs field transforms for optical flow. In European Conference on Computer Vision. Springer, 402–419.
34. Ondřej Texler, David Futschik, Michal Kučera, Ondřej Jamriška, Šárka Sochorová, Menclei Chai, Sergey Tulyakov, and Daniel Sỳkora. 2020. Interactive video stylization using few-shot patch-based training. ACM Transactions on Graphics (TOG) 39, 4 (2020), 73–1.
35. Dmitry Ulyanov, Andrea Vedaldi, and Victor Lempitsky. 2018. Deep image prior. In Proceedings of the IEEE conference on computer vision and pattern recognition. 9446–9454.
36. John YA Wang and Edward H Adelson. 1994. Representing moving images with layers. IEEE transactions on image processing 3, 5 (1994), 625–638.
37. Xiaolong Wang, Allan Jabri, and Alexei A Efros. 2019. Learning correspondence from the cycle-consistency of time. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2566–2576.
38. Fanbo Xiang, Zexiang Xu, Miloš Hašan, Yannick Hold-Geoffroy, Kalyan Sunkavalli, and Hao Su. 2021. NeuTex: Neural Texture Mapping for Volumetric Neural Rendering. arXiv preprint arXiv:2103.00762 (2021).