
“Synthesizing light field from a single image with variable MPI and two network fusion” by Li and Kalantari
Conference:
Type(s):
Title:
- Synthesizing light field from a single image with variable MPI and two network fusion
Session/Category Title:
- Learning New Viewpoints
Presenter(s)/Author(s):
Abstract:
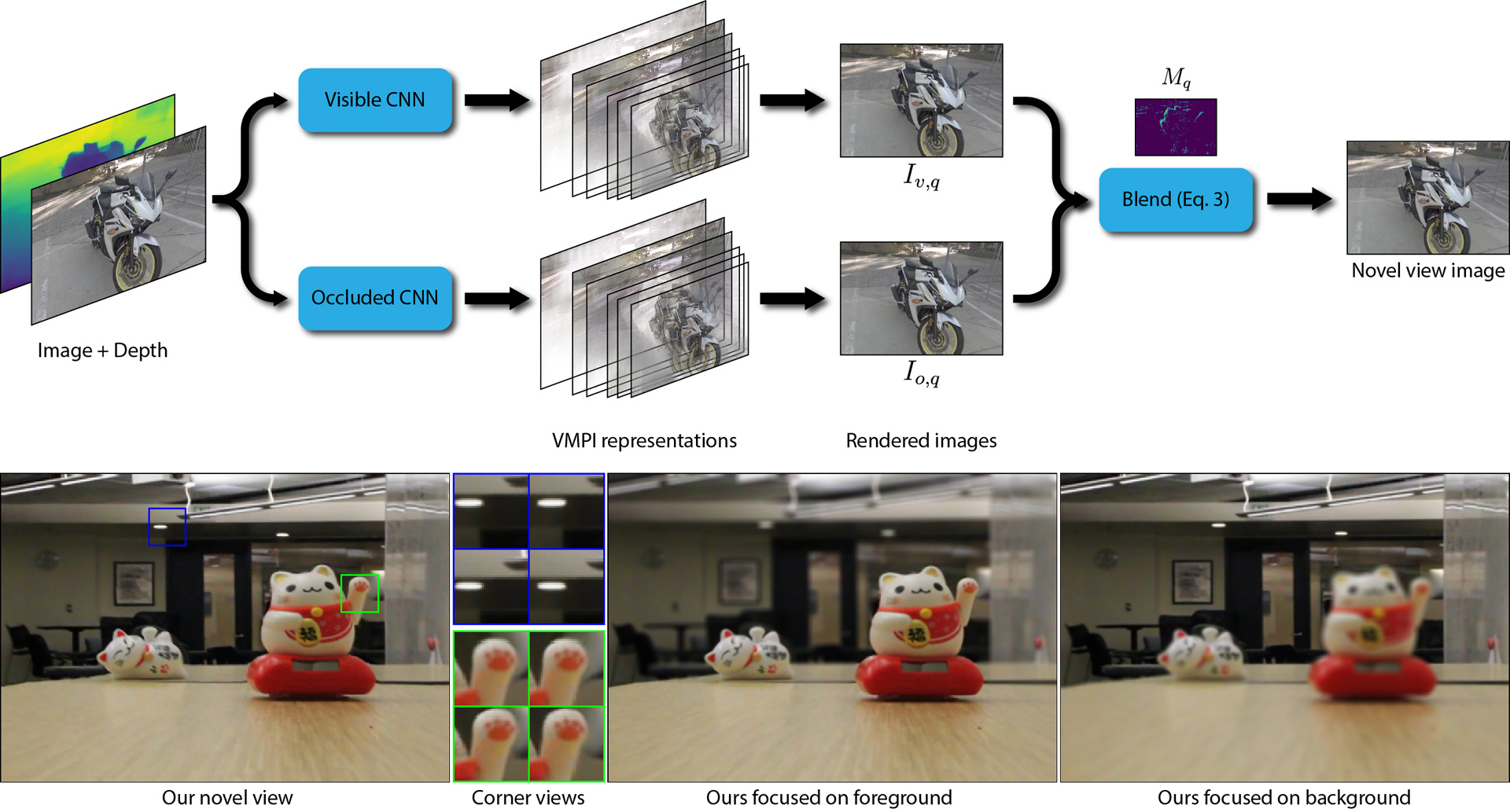
We propose a learning-based approach to synthesize a light field with a small baseline from a single image. We synthesize the novel view images by first using a convolutional neural network (CNN) to promote the input image into a layered representation of the scene. We extend the multiplane image (MPI) representation by allowing the disparity of the layers to be inferred from the input image. We show that, compared to the original MPI representation, our representation models the scenes more accurately. Moreover, we propose to handle the visible and occluded regions separately through two parallel networks. The synthesized images using these two networks are then combined through a soft visibility mask to generate the final results. To effectively train the networks, we introduce a large-scale light field dataset of over 2,000 unique scenes containing a wide range of objects. We demonstrate that our approach synthesizes high-quality light fields on a variety of scenes, better than the state-of-the-art methods.
References:
1. Gaurav Chaurasia, Sylvain Duchene, Olga Sorkine-Hornung, and George Drettakis. 2013. Depth synthesis and local warps for plausible image-based navigation. ACM Transactions on Graphics (TOG) 32, 3 (2013), 1–12.Google ScholarDigital Library
2. Qifeng Chen and Vladlen Koltun. 2017. Photographic image synthesis with cascaded refinement networks. In Proceedings of the IEEE International Conference on Computer Vision. 1511–1520.Google ScholarCross Ref
3. Inchang Choi, Orazio Gallo, Alejandro Troccoli, Min H Kim, and Jan Kautz. 2019. Extreme View Synthesis. In Proceedings of the IEEE International Conference on Computer Vision. 7781–7790.Google ScholarCross Ref
4. X. Cun, F. Xu, C. Pun, and H. Gao. 2019. Depth-Assisted Full Resolution Network for Single Image-Based View Synthesis. IEEE Computer Graphics and Applications 39, 2 (March 2019), 52–64.Google ScholarCross Ref
5. Donald G. Dansereau, Bernd Girod, and Gordon Wetzstein. 2019. LiFF: Light Field Features in Scale and Depth. In Computer Vision and Pattern Recognition (CVPR). IEEE.Google Scholar
6. Helisa Dhamo, Keisuke Tateno, Iro Laina, Nassir Navab, and Federico Tombari. 2019. Peeking behind objects: Layered depth prediction from a single image. Pattern Recognition Letters 125 (2019), 333–340.Google ScholarCross Ref
7. Simon Evain and Christine Guillemot. 2019. A Lightweight Neural Network for Monocular View Generation with Occlusion Handling. IEEE Transactions on Pattern Analysis and Machine Intelligence (2019), 1–14.Google ScholarCross Ref
8. John Flynn, Michael Broxton, Paul Debevec, Matthew DuVall, Graham Fyffe, Ryan Overbeck, Noah Snavely, and Richard Tucker. 2019. DeepView: View synthesis with learned gradient descent. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2367–2376.Google ScholarCross Ref
9. John Flynn, Ivan Neulander, James Philbin, and Noah Snavely. 2016. Deepstereo: Learning to predict new views from the world’s imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 5515–5524.Google Scholar
10. Yoav HaCohen, Eli Shechtman, Dan B Goldman, and Dani Lischinski. 2011. Non-rigid dense correspondence with applications for image enhancement. ACM Transactions on Graphics (TOG) 30, 4 (2011), 70.Google ScholarDigital Library
11. Peter Hedman, Suhib Alsisan, Richard Szeliski, and Johannes Kopf. 2017. Casual 3D photography. ACM Transactions on Graphics (TOG) 36, 6 (2017), 1–15.Google ScholarDigital Library
12. Peter Hedman and Johannes Kopf. 2018. Instant 3d photography. ACM Transactions on Graphics (TOG) 37, 4 (2018), 1–12.Google ScholarDigital Library
13. Sergey Ioffe and Christian Szegedy. 2015. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167 (2015).Google ScholarDigital Library
14. Nima Khademi Kalantari, Ting-Chun Wang, and Ravi Ramamoorthi. 2016. Learning-based view synthesis for light field cameras. ACM Transactions on Graphics (TOG) 35, 6 (2016), 193.Google ScholarDigital Library
15. Diederick P Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. In International Conference on Learning Representations (ICLR).Google Scholar
16. Miaomiao Liu, Xuming He, and Mathieu Salzmann. 2018. Geometry-aware deep network for single-image novel view synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4616–4624.Google ScholarCross Ref
17. Ben Mildenhall, Pratul P. Srinivasan, Rodrigo Ortiz-Cayon, Nima Khademi Kalantari, Ravi Ramamoorthi, Ren Ng, and Abhishek Kar. 2019. Local Light Field Fusion: Practical View Synthesis with Prescriptive Sampling Guidelines. ACM Transactions on Graphics (TOG) 38, 4, Article 29 (July 2019), 14 pages.Google ScholarDigital Library
18. Simon Niklaus, Long Mai, Jimei Yang, and Feng Liu. 2019. 3D Ken Burns Effect from a Single Image. ACM Transactions on Graphics (TOG) 38, 6, Article Article 184 (Nov. 2019), 15 pages.Google ScholarDigital Library
19. Kyle Olszewski, Sergey Tulyakov, Oliver Woodford, Hao Li, and Linjie Luo. 2019. Transformable Bottleneck Networks. arXiv preprint arXiv:1904.06458 (2019).Google Scholar
20. Eunbyung Park, Jimei Yang, Ersin Yumer, Duygu Ceylan, and Alexander C Berg. 2017. Transformation-grounded image generation network for novel 3d view synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 3500–3509.Google ScholarCross Ref
21. Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. PyTorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems. 8024–8035.Google Scholar
22. Eric Penner and Li Zhang. 2017. Soft 3D reconstruction for view synthesis. ACM Transactions on Graphics (TOG) 36, 6 (2017), 235.Google ScholarDigital Library
23. Thomas Porter and Tom Duff. 1984. Compositing digital images. In ACM Siggraph Computer Graphics, Vol. 18. ACM, 253–259.Google ScholarDigital Library
24. Konstantinos Rematas, Chuong H Nguyen, Tobias Ritschel, Mario Fritz, and Tinne Tuytelaars. 2016. Novel views of objects from a single image. IEEE Transactions on Pattern Analysis and Machine Intelligence 39, 8 (2016), 1576–1590.Google ScholarDigital Library
25. Meng-Li Shih, Shih-Yang Su, Johannes Kopf, and Jia-Bin Huang. 2020. 3D Photography using Context-aware Layered Depth Inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8028–8038.Google ScholarCross Ref
26. Pratul P Srinivasan, Richard Tucker, Jonathan T Barron, Ravi Ramamoorthi, Ren Ng, and Noah Snavely. 2019. Pushing the Boundaries of View Extrapolation with Multiplane Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 175–184.Google ScholarCross Ref
27. Pratul P Srinivasan, Tongzhou Wang, Ashwin Sreelal, Ravi Ramamoorthi, and Ren Ng. 2017. Learning to synthesize a 4d rgbd light field from a single image. In Proceedings of the IEEE International Conference on Computer Vision. 2243–2251.Google ScholarCross Ref
28. Maxim Tatarchenko, Alexey Dosovitskiy, and Thomas Brox. 2015. Single-view to Multi-view: Reconstructing Unseen Views with a Convolutional Network. CoRR abs/1511.06702 (2015).Google Scholar
29. Richard Tucker and Noah Snavely. 2020. Single-View View Synthesis with Multiplane Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 551–560.Google ScholarCross Ref
30. Shubham Tulsiani, Richard Tucker, and Noah Snavely. 2018. Layer-structured 3d scene inference via view synthesis. In Proceedings of the European Conference on Computer Vision (ECCV). 302–317.Google ScholarCross Ref
31. Lijun Wang, Xiaohui Shen, Jianming Zhang, Oliver Wang, Zhe Lin, Chih-Yao Hsieh, Sarah Kong, and Huchuan Lu. 2018b. DeepLens: Shallow Depth of Field from a Single Image. ACM Transactions on Graphics (TOG) 37, 6, Article 245 (Dec. 2018), 11 pages.Google Scholar
32. Ting-Chun Wang, Jun-Yan Zhu, Nima Khademi Kalantari, Alexei A Efros, and Ravi Ramamoorthi. 2017. Light field video capture using a learning-based hybrid imaging system. ACM Transactions on Graphics (TOG) 36, 4 (2017), 133.Google ScholarDigital Library
33. Yunlong Wang, Fei Liu, Zilei Wang, Guangqi Hou, Zhenan Sun, and Tieniu Tan. 2018a. End-to-end view synthesis for light field imaging with pseudo 4DCNN. In Proceedings of the European Conference on Computer Vision (ECCV). 333–348.Google ScholarCross Ref
34. Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. 2004. Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing 13, 4 (2004), 600–612.Google ScholarDigital Library
35. Olivia Wiles, Georgia Gkioxari, Richard Szeliski, and Justin Johnson. 2020. Synsin: End-to-end view synthesis from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7467–7477.Google ScholarCross Ref
36. Gaochang Wu, Mandan Zhao, Liangyong Wang, Qionghai Dai, Tianyou Chai, and Yebin Liu. 2017. Light field reconstruction using deep convolutional network on EPI. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 6319–6327.Google ScholarCross Ref
37. Xinchen Yan, Jimei Yang, Ersin Yumer, Yijie Guo, and Honglak Lee. 2016. Perspective transformer nets: Learning single-view 3d object reconstruction without 3d supervision. In Advances in Neural Information Processing Systems. 1696–1704.Google Scholar
38. Jimei Yang, Scott E Reed, Ming-Hsuan Yang, and Honglak Lee. 2015. Weakly-supervised disentangling with recurrent transformations for 3d view synthesis. In Advances in Neural Information Processing Systems. 1099–1107.Google Scholar
39. Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. 2018. Stereo Magnification: Learning View Synthesis Using Multiplane Images. ACM Transactions on Graphics (TOG) 37, 4, Article 65 (July 2018), 12 pages.Google ScholarDigital Library
40. Tinghui Zhou, Shubham Tulsiani, Weilun Sun, Jitendra Malik, and Alexei A Efros. 2016. View synthesis by appearance flow. In European Conference on Computer Vision. Springer, 286–301.Google ScholarCross Ref