
“Whippletree: task-based scheduling of dynamic workloads on the GPU” by Steinberger, Kenzel, Boechat, Kerbl, Dokter, et al. …
Conference:
Type(s):
Title:
- Whippletree: task-based scheduling of dynamic workloads on the GPU
Session/Category Title:
- Vectors and Shaders
Presenter(s)/Author(s):
Abstract:
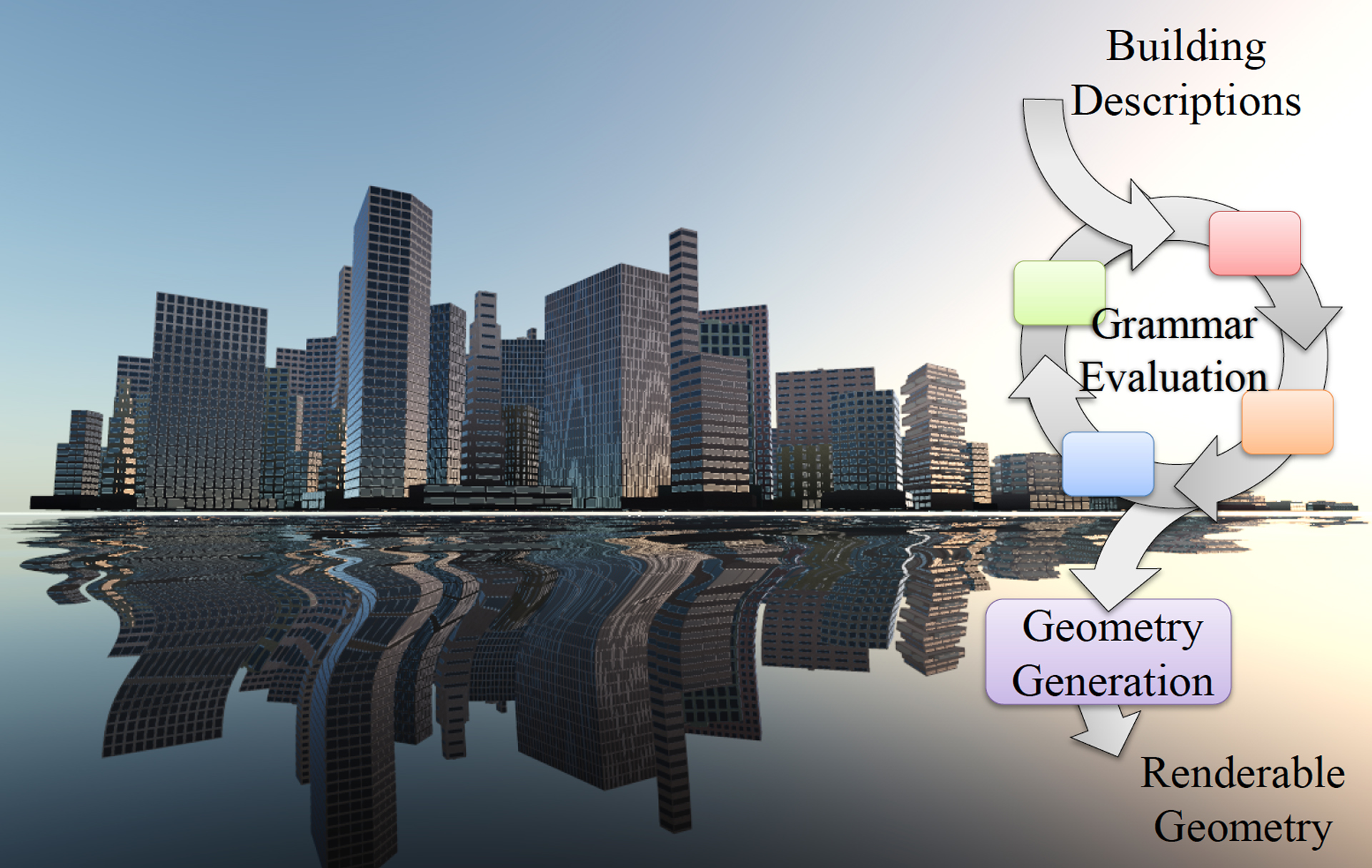
In this paper, we present Whippletree, a novel approach to scheduling dynamic, irregular workloads on the GPU. We introduce a new programming model which offers the simplicity and expressiveness of task-based parallelism while retaining all aspects of the multi-level execution hierarchy essential to unlocking the full potential of a modern GPU. At the same time, our programming model lends itself to efficient implementation on the SIMD-based architecture typical of a current GPU. We demonstrate the practical utility of our model by providing a reference implementation on top of current CUDA hardware. Furthermore, we show that our model compares favorably to traditional approaches in terms of both performance as well as the range of applications that can be covered. We demonstrate the benefits of our model for recursive Reyes rendering, procedural geometry generation and volume rendering with concurrent irradiance caching.
References:
1. Aila, T., and Laine, S. 2009. Understanding the efficiency of ray traversal on GPUs. In Proc. HPG, 145–149.
2. Breitbart, J. 2011. Static GPU threads and an improved scan algorithm. In Proc. Euro-Par 2010, 373–380.
3. Cederman, D., and Tsigas, P. 2008. On dynamic load balancing on graphics processors. In Proc. Graphics Hardware, 57–64.
4. Chatterjee, S., Grossman, M., Sbirlea, A., and Sarkar, V. 2011. Dynamic task parallelism with a GPU work-stealing runtime system. In Proc. Languages and Compilers for Parallel Computing.
5. Chen, L., Villa, O., Krishnamoorthy, S., and Gao, G. 2010. Dynamic load balancing on single- and multi-gpu systems. In IEEE Parallel Distributed Processing.
6. Cook, R. L., Carpenter, L., and Catmull, E. 1987. The reyes image rendering architecture. SIGGRAPH Comput. Graph. 21, 4 (Aug.), 95–102.
7. Hargreaves, S. 2005. Generating shaders from HLSL fragments. ShaderX3: Advanced rendering with DirectX and OpenGL.
8. Hoberock, J., Lu, V., Jia, Y., and Hart, J. C. 2009. Stream compaction for deferred shading. In Proc. HPG, 173–180.
9. Kroes, T., Post, F. H., and Botha, C. P. 2012. Exposure render: An interactive photo-realistic volume rendering framework. PLoS ONE 7, 7 (07).
10. Laine, S., Karras, T., and Aila, T. 2013. Megakernels considered harmful: Wavefront path tracing on GPUs. In Proc. HPG.
11. Liu, F., Huang, M.-C., Liu, X.-H., and Wu, E.-H. 2010. Freepipe: A programmable parallel rendering architecture for efficient multi-fragment effects. In Proc. I3D, 75–82.
12. Luo, L., Wong, M., and Hwu, W.-M. 2010. An effective GPU implementation of breadth-first search. In Proc. Design Automation Conference, ACM, 52–55.
13. NVIDIA. 2012. CUDA Dynamic Parallelism Programming Guide.
14. Parker, S. G., Bigler, J., Dietrich, A., Friedrich, H., Hoberock, J., Luebke, D., McAllister, D., McGuire, M., Morley, K., Robison, A., and Stich, M. 2010. Optix: a general purpose ray tracing engine. ACM TOG 29, 4(66).
15. Patney, A., and Owens, J. D. 2008. Real-time Reyes-style adaptive surface subdivision. ACM TOG 27, 5(143).
16. Satish, N., Harris, M., and Garland, M. 2009. Designing efficient sorting algorithms for manycore GPUs. In Proc. IEEE Parallel&Distributed Processing.
17. Steinberger, M., Kainz, B., Kerbl, B., Hauswiesner, S., Kenzel, M., and Schmalstieg, D. 2012. Softshell: Dynamic scheduling on GPUs. ACM TOG 31, 6(161).
18. Steinberger, M., Kenzel, M., Kainz, B., Müller, J., Wonka, P., and Schmalstieg, D. 2014. Parallel generation of architecture on the GPU. In Computer Graphics Forum, vol. 33, 73–82.
19. Stuart, J. A., and Owens, J. D. 2009. Message passing on data-parallel architectures. In Proc. Parallel&Distributed Processing, IEEE.
20. Sugerman, J., Fatahalian, K., Boulos, S., Akeley, K., and Hanrahan, P. 2009. GRAMPS: A programming model for graphics pipelines. ACM TOG 28, 1, 4:1–4:11.
21. Tzeng, S., Patney, A., and Owens, J. D. 2010. Task management for irregular-parallel workloads on the GPU. In Proc. HPG, 29–37.
22. Xiao, S., and Feng, W. 2010. Inter-block GPU communication via fast barrier synchronization. In IEEE Parallel Distributed Processing.
23. Yan, S., Long, G., and Zhang, Y. 2013. Streamscan: fast scan algorithms for GPUs without global barrier synchronization. In ACM Principles and Practice of Parallel Programming, 229–238.
24. Zhou, K., Hou, Q., Ren, Z., Gong, M., Sun, X., and Guo, B. 2009. RenderAnts: interactive Reyes rendering on GPUs. ACM TOG 28, 5 (Dec.), 155:1–155:11.