
“DAE-Net: Deforming Auto-Encoder for Fine-grained Shape Co-segmentation”
Conference:
Type(s):
Title:
- DAE-Net: Deforming Auto-Encoder for Fine-grained Shape Co-segmentation
Presenter(s)/Author(s):
Abstract:
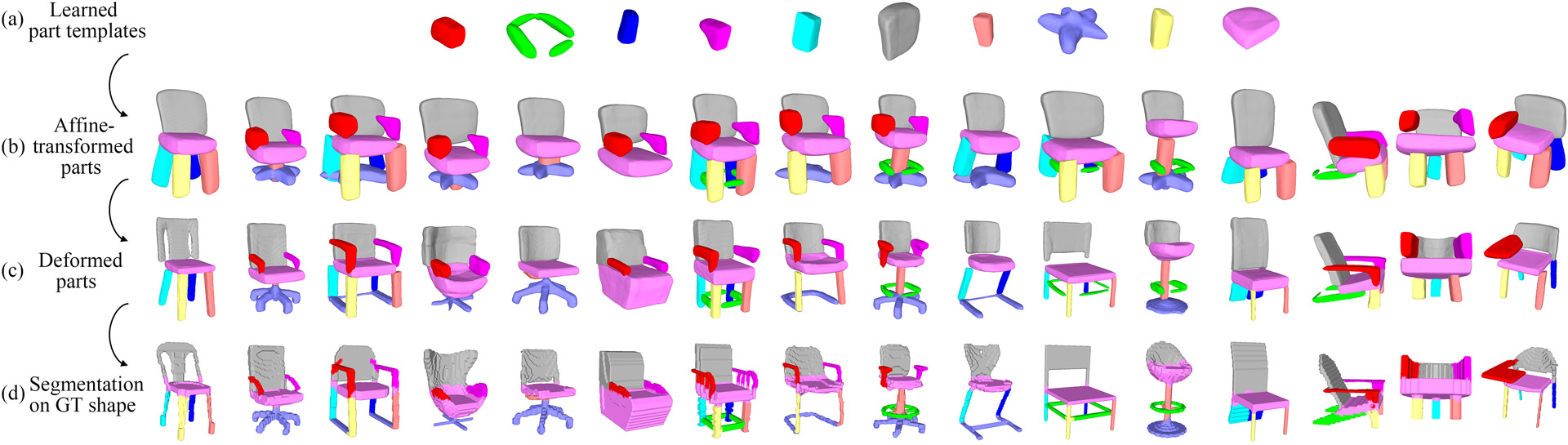
We present an unsupervised 3D shape co-segmentation method following the stipulation that corresponding parts in different shapes should have approximately the same shape. Our method learns the shapes of a set of part templates and composes each shape by selecting a subset of template parts which are affine-transformed and deformed.
References:
[1]
Ahmed Abdelreheem, Abdelrahman Eldesokey, Maks Ovsjanikov, and Peter Wonka. 2023a. Zero-shot 3D shape correspondence. In SIGGRAPH Asia 2023 Conference Papers. 1?11.
[2]
Ahmed Abdelreheem, Ivan Skorokhodov, Maks Ovsjanikov, and Peter Wonka. 2023b. SATR: Zero-shot semantic segmentation of 3D Shapes. In ICCV.
[3]
Jean-Baptiste Alayrac 2022. Flamingo: a visual language model for few-shot learning. NeurIPS (2022).
[4]
Federica Bogo, Javier Romero, Gerard Pons-Moll, and Michael J. Black. 2017. Dynamic FAUST: Registering Human Bodies in Motion. In CVPR.
[5]
Maxime Bucher, Tuan-Hung Vu, Matthieu Cord, and Patrick P?rez. 2019. Zero-shot semantic segmentation. NeurIPS (2019).
[6]
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv? J?gou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. 2021. Emerging properties in self-supervised vision transformers. In CVPR.
[7]
Angel X. Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianxiong Xiao, Li Yi, and Fisher Yu. 2015. ShapeNet: An Information-Rich 3D Model Repository. arXiv (2015).
[8]
Siddhartha Chaudhuri, Daniel Ritchie, Jiajun Wu, Kai Xu, and Hao Zhang. 2020. Learning Generative Models of 3D Structures. Computer Graphics Forum (Eurographics STAR) (2020).
[9]
Ding-Jie Chen, Hwann-Tzong Chen, and Long-Wen Chang. 2012. Video object cosegmentation. In Proceedings of the 20th ACM international conference on Multimedia.
[10]
Runnan Chen, Xinge Zhu, Nenglun Chen, Wei Li, Yuexin Ma, Ruigang Yang, and Wenping Wang. 2022. Zero-shot point cloud segmentation by transferring geometric primitives. arXiv (2022).
[11]
Zhiqin Chen, Vladimir G. Kim, Matthew Fisher, Noam Aigerman, Hao Zhang, and Siddhartha Chaudhuri. 2021. DECOR-GAN: 3D Shape Detailization by Conditional Refinement. CVPR (2021).
[12]
Zhiqin Chen, Andrea Tagliasacchi, and Hao Zhang. 2020. BSP-Net: Generating Compact Meshes via Binary Space Partitioning. CVPR (2020).
[13]
Zhiqin Chen, Kangxue Yin, Matthew Fisher, Siddhartha Chaudhuri, and Hao Zhang. 2019. BAE-NET: Branched Autoencoder for Shape Co-Segmentation. ICCV (2019).
[14]
Zhiqin Chen and Hao Zhang. 2019. Learning Implicit Fields for Generative Shape Modeling. CVPR (2019).
[15]
Dale Decatur, Itai Lang, and Rana Hanocka. 2023. 3D Highlighter: Localizing regions on 3D shapes via text descriptions. In CVPR.
[16]
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. 2023. Objaverse: A universe of annotated 3d objects. In CVPR.
[17]
Boyang Deng, Kyle Genova, Soroosh Yazdani, Sofien Bouaziz, Geoffrey Hinton, and Andrea Tagliasacchi. 2020. CvxNet: Learnable convex decomposition. In CVPR.
[18]
Yu Deng, Jiaolong Yang, and Xin Tong. 2021. Deformed implicit field: Modeling 3d shapes with learned dense correspondence. In CVPR. 10286?10296.
[19]
Theo Deprelle, Thibault Groueix, Matthew Fisher, Vladimir Kim, Bryan Russell, and Mathieu Aubry. 2019. Learning elementary structures for 3D shape generation and matching. NeurIPS (2019).
[20]
Runyu Ding, Jihan Yang, Chuhui Xue, Wenqing Zhang, Song Bai, and Xiaojuan Qi. 2023. PLA: Language-driven open-vocabulary 3D scene understanding. In CVPR.
[21]
Zhiwen Fan, Peihao Wang, Yifan Jiang, Xinyu Gong, Dejia Xu, and Zhangyang Wang. 2022. NeRF-SOS: Any-view self-supervised object segmentation on complex scenes. In ICLR.
[22]
Xiao Fu, Shangzhan Zhang, Tianrun Chen, Yichong Lu, Lanyun Zhu, Xiaowei Zhou, Andreas Geiger, and Yiyi Liao. 2022. Panoptic NeRF: 3D-to-2D label transfer for panoptic urban scene segmentation. In 3DV.
[23]
Rahul Goel, Dhawal Sirikonda, Saurabh Saini, and PJ Narayanan. 2023. Interactive segmentation of radiance fields. In CVPR.
[24]
A. Golovinskiy and T. Funkhouser. 2009a. Consistent segmentation of 3D models. Computers & Graphics (Proc. of SMI) 33, 3 (2009), 262?269.
[25]
Aleksey Golovinskiy and Thomas Funkhouser. 2009b. Consistent segmentation of 3D models. Computers & Graphics (2009).
[26]
Geoffrey E Hinton, Alex Krizhevsky, and Sida D Wang. 2011. Transforming auto-encoders. In International Conference on Artificial Neural Networks.
[27]
Yining Hong, Chunru Lin, Yilun Du, Zhenfang Chen, Joshua B Tenenbaum, and Chuang Gan. 2023. 3D concept learning and reasoning from multi-view images. In CVPR.
[28]
Ruizhen Hu, Lubin Fan, and Ligang Liu. 2012. Co-segmentation of 3D shapes via subspace clustering. In Comput. Graph. Forum.
[29]
Qixing Huang and Leonidas Guibas. 2013. Consistent shape maps via semidefinite programming. Computer Graphics Forum (SGP) 32, 5 (2013), 177?186.
[30]
Qixing Huang, Vladlen Koltun, and Leonidas Guibas. 2011. Joint shape segmentation with linear programming. ACM TOG (2011).
[31]
Xiaoyang Huang, Yi Zhang, Kai Chen, Teng Li, Wenjun Zhang, and Bingbing Ni. 2023. Learning Shape Primitives via Implicit Convexity Regularization. In ICCV. 3642?3651.
[32]
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. 2021. Scaling up visual and vision-language representation learning with noisy text supervision. In ICML.
[33]
Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Lovegrove. 2019. DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation. In CVPR.
[34]
Yuki Kawana, Yusuke Mukuta, and Tatsuya Harada. 2020. Neural star domain as primitive representation. NeurIPS (2020).
[35]
Sihyeon Kim, Minseok Joo, Jaewon Lee, Juyeon Ko, Juhan Cha, and Hyunwoo J Kim. 2023. Semantic-Aware Implicit Template Learning via Part Deformation Consistency. In ICCV. 593?603.
[36]
Diederik P. Kingma and Jimmy Ba. 2015. Adam: a method for stochastic optimization. In ICLR.
[37]
Sosuke Kobayashi, Eiichi Matsumoto, and Vincent Sitzmann. 2022. Decomposing NeRF for editing via feature field distillation. NeurIPS (2022).
[38]
Juil Koo, Ian Huang, Panos Achlioptas, Leonidas J Guibas, and Minhyuk Sung. 2022. PartGlot: Learning shape part segmentation from language reference games. In CVPR.
[39]
Abhijit Kundu, Kyle Genova, Xiaoqi Yin, Alireza Fathi, Caroline Pantofaru, Leonidas J Guibas, Andrea Tagliasacchi, Frank Dellaert, and Thomas Funkhouser. 2022. Panoptic neural fields: A semantic object-aware neural scene representation. In CVPR.
[40]
Boyi Li, Kilian Q Weinberger, Serge Belongie, Vladlen Koltun, and Rene Ranftl. 2022a. Language-driven Semantic Segmentation. In ICLR.
[41]
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, 2022b. Grounded language-image pre-training. In CVPR.
[42]
Minghua Liu, Yinhao Zhu, Hong Cai, Shizhong Han, Zhan Ling, Fatih Porikli, and Hao Su. 2023. PartSLIP: Low-shot part segmentation for 3D point clouds via pretrained image-language models. In CVPR.
[43]
Stephen Lombardi, Tomas Simon, Jason Saragih, Gabriel Schwartz, Andreas Lehrmann, and Yaser Sheikh. 2019. Neural volumes: learning dynamic renderable volumes from images. ACM TOG (2019).
[44]
Min Meng, Jiazhi Xia, Jun Luo, and Ying He. 2013. Unsupervised co-segmentation for 3D shapes using iterative multi-label optimization. CAD (2013).
[45]
Lars Mescheder, Michael Oechsle, Michael Niemeyer, Sebastian Nowozin, and Andreas Geiger. 2019. Occupancy Networks: Learning 3D Reconstruction in Function Space. In CVPR.
[46]
Bj?rn Michele, Alexandre Boulch, Gilles Puy, Maxime Bucher, and Renaud Marlet. 2021. Generative zero-shot learning for semantic segmentation of 3D point clouds. In 3DV.
[47]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. 2021. NeRF: Representing scenes as neural radiance fields for view synthesis. In ECCV.
[48]
Niloy Mitra, Michael Wand, Hao Zhang, Daniel Cohen-Or, and Martin Bokeloh. 2013. Structure-aware shape processing. In SIGGRAPH Asia Course.
[49]
Chengjie Niu, Manyi Li, Kai Xu, and Hao Zhang. 2022. RIM-Net: Recursive implicit fields for unsupervised learning of hierarchical shape structures. In CVPR.
[50]
Despoina Paschalidou, Luc Van Gool, and Andreas Geiger. 2020. Learning unsupervised hierarchical part decomposition of 3D objects from a single rgb image. In CVPR.
[51]
Despoina Paschalidou, Angelos Katharopoulos, Andreas Geiger, and Sanja Fidler. 2021. Neural Parts: Learning expressive 3D shape abstractions with invertible neural networks. In CVPR.
[52]
Despoina Paschalidou, Ali Osman Ulusoy, and Andreas Geiger. 2019. Superquadrics revisited: Learning 3D shape parsing beyond cuboids. In CVPR.
[53]
Songyou Peng, Kyle Genova, Chiyu Jiang, Andrea Tagliasacchi, Marc Pollefeys, Thomas Funkhouser, 2023. Openscene: 3d scene understanding with open vocabularies. In CVPR. 815?824.
[54]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, 2021. Learning transferable visual models from natural language supervision. In ICML.
[55]
Sara Sabour, Nicholas Frosst, and Geoffrey E Hinton. 2017. Dynamic routing between capsules. NeurIPS (2017).
[56]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, 2022. Photorealistic text-to-image diffusion models with deep language understanding. NeurIPS (2022).
[57]
Ariel Shamir. 2008. A survey on mesh segmentation techniques. In Comput. Graph. Forum.
[58]
Zhenyu Shu, Chengwu Qi, Shiqing Xin, Chao Hu, Li Wang, Yu Zhang, and Ligang Liu. 2016. Unsupervised 3D shape segmentation and co-segmentation via deep learning. CAGD (2016).
[59]
Qingyao Shuai, Chi Zhang, Kaizhi Yang, and Xuejin Chen. 2023. DPF-Net: Combining Explicit Shape Priors in Deformable Primitive Field for Unsupervised Structural Reconstruction of 3D Objects. In ICCV. 14321?14329.
[60]
Yawar Siddiqui, Lorenzo Porzi, Samuel Rota Bul?, Norman M?ller, Matthias Nie?ner, Angela Dai, and Peter Kontschieder. 2023. Panoptic lifting for 3D scene understanding with neural fields. In CVPR.
[61]
Oana Sidi, Oliver van Kaick, Yanir Kleiman, Hao Zhang, and Daniel Cohen-Or. 2011. Unsupervised co-segmentation of a set of shapes via descriptor-space spectral clustering. ACM TOG (2011).
[62]
Chun-Yu Sun, Qian-Fang Zou, Xin Tong, and Yang Liu. 2019. Learning adaptive hierarchical cuboid abstractions of 3D shape collections. ACM TOG (2019).
[63]
Konstantinos Tertikas, Despoina Paschalidou, Boxiao Pan, Jeong Joon Park, Mikaela Angelina Uy, Ioannis Emiris, Yannis Avrithis, and Leonidas Guibas. 2023. Generating Part-Aware Editable 3D Shapes Without 3D Supervision. In CVPR.
[64]
Vadim Tschernezki, Iro Laina, Diane Larlus, and Andrea Vedaldi. 2022. Neural Feature Fusion Fields: 3D distillation of self-supervised 2D image representations. In 3DV.
[65]
Shubham Tulsiani, Hao Su, Leonidas J Guibas, Alexei A Efros, and Jitendra Malik. 2017. Learning shape abstractions by assembling volumetric primitives. In CVPR.
[66]
Oliver van Kaick, Kai Xu, Hao Zhang, Yanzhen Wang, Shuyang Sun, Ariel Shamir, and Daniel Cohen-Or. 2013. Co-Hierarchical Analysis of Shape Structures. ACM TOG 32, 4 (2013), Article 69.
[67]
Sara Vicente, Carsten Rother, and Vladimir Kolmogorov. 2011. Object cosegmentation. In CVPR. 2217?2224.
[68]
Suhani Vora, Noha Radwan, Klaus Greff, Henning Meyer, Kyle Genova, Mehdi SM Sajjadi, Etienne Pot, Andrea Tagliasacchi, and Daniel Duckworth. 2021. NeSF: Neural semantic fields for generalizable semantic segmentation of 3D scenes. arXiv (2021).
[69]
Kai Xu, Vladimir G. Kim, Qixing Huang, Niloy Mitra, and Evangelos Kalogerakis. 2016. Data-Driven Shape Analysis and Processing. In SIGGRAPH Asia Course.
[70]
Kai Xu, Honghua Li, Hao Zhang, Daniel Cohen-Or, Yueshan Xiong, and Zhi-Quan Cheng. 2010. Style-content separation by anisotropic part scales. ACM TOG (2010).
[71]
Cheng-Kun Yang, Yung-Yu Chuang, and Yen-Yu Lin. 2021. Unsupervised point cloud object co-segmentation by co-contrastive learning and mutual attention sampling. In ICCV.
[72]
Cheng-Kun Yang, Ji-Jia Wu, Kai-Syun Chen, Yung-Yu Chuang, and Yen-Yu Lin. 2022. An MIL-derived transformer for weakly supervised point cloud segmentation. In CVPR.
[73]
Kaizhi Yang and Xuejin Chen. 2021. Unsupervised learning for cuboid shape abstraction via joint segmentation from point clouds. ACM Transactions on Graphics (TOG) 40, 4 (2021), 1?11.
[74]
Li Yi, Vladimir G Kim, Duygu Ceylan, I Shen, Mengyan Yan, Hao Su, Cewu Lu, Qixing Huang, Alla Sheffer, Leonidas Guibas, 2016. A scalable active framework for region annotation in 3D shape collections. ACM TOG (2016).
[75]
Haotian Zhang, Pengchuan Zhang, Xiaowei Hu, Yen-Chun Chen, Liunian Li, Xiyang Dai, Lijuan Wang, Lu Yuan, Jenq-Neng Hwang, and Jianfeng Gao. 2022. GLIPv2: Unifying localization and vision-language understanding. NeurIPS (2022).
[76]
Zerong Zheng, Tao Yu, Qionghai Dai, and Yebin Liu. 2021. Deep implicit templates for 3d shape representation. In CVPR. 1429?1439.
[77]
Shuaifeng Zhi, Tristan Laidlow, Stefan Leutenegger, and Andrew J Davison. 2021. In-place scene labelling and understanding with implicit scene representation. In ICCV.
[78]
Chenyang Zhu, Kai Xu, Siddhartha Chaudhuri, Li Yi, Leonidas J Guibas, and Hao Zhang. 2020. AdaCoSeg: Adaptive shape co-segmentation with group consistency loss. In CVPR.